

ÖZET
Açıklanabilir Yapay Zeka (XAI) Rehberi: Makine Öğrenimi Modellerini Anlama ve Yorumlama 2026
Makine öğrenimi modellerinin nasıl kararlar aldığını anlamak için Açıklanabilir Yapay Zeka (XAI) tekniklerini keşfedin. SHAP, LIME gibi yöntemlerle modellerinizi daha şeffaf hale getirin.
Keywords: Yapay Zeka, Makine Öğrenimi, XAI
İÇİNDEKİLER
1. Arka Plan ve Giriş: Neden Açıklanabilirlik Önemli?
2. XAI Teknikleri ve Yaklaşımları: Kara Kutu Modellerini Aydınlatmak
3. XAI Uygulamasındaki Zorluklar ve Çözümler
4. Pratik Uygulama: XAI ile Model Şeffaflığı Nasıl Artırılır?
5. Vaka Çalışmaları ve Endüstriyel Uygulamalar
6. Gelecek Öngörüsü ve Etik Boyutlar
7. Sıkça Sorulan Sorular
GİRİŞ
Arka Plan ve Giriş: Neden Açıklanabilirlik Önemli?
Yapay Zeka (YZ) ve Makine Öğrenimi (ML) modelleri, günlük hayatımızın her alanına hızla entegre oluyor. Finanstan sağlığa, hukuktan otonom sistemlere kadar birçok kritik sektörde karar verme süreçlerini dönüştürüyorlar. Ancak bu modellerin karmaşıklığı arttıkça, özellikle derin öğrenme gibi tekniklerle, “kara kutu” problemi ortaya çıkıyor. Yani, bir modelin belirli bir kararı neden verdiğini anlamak veya yorumlamak giderek zorlaşıyor. İşte tam bu noktada, Açıklanabilir Yapay Zeka (XAI – Explainable AI) devreye giriyor.
XAI, makine öğrenimi modellerinin iç işleyişini, karar alma mekanizmalarını ve çıktılarını insanlar tarafından anlaşılabilir hale getirmeyi amaçlayan bir dizi teknik ve metodolojiyi kapsar. 2026 yılı itibarıyla, XAI sadece akademik bir merak olmaktan çıkmış, yasal düzenlemeler (örneğin, Avrupa Birliği’nin YZ Yasası), etik kaygılar ve iş dünyasının güven ihtiyacı nedeniyle zorunlu bir gereklilik haline gelmiştir.
Bir YZ modelinin neden belirli bir kredi başvurusunu reddettiğini, bir hastalığı teşhis ettiğini veya otonom bir aracın belirli bir anda neden fren yaptığını açıklayabilmek, sadece teknik bir gereklilik değil, aynı zamanda toplumsal güven, adalet ve hesap verebilirlik açısından da hayati öneme sahiptir. Örneğin, sağlık sektöründe yanlış bir teşhisin sonuçları ölümcül olabilirken, finans sektöründe ayrımcı kararlar yasal yaptırımlara yol açabilir. Bu nedenle, YZ sistemlerinin şeffaflığı, güvenilirliği ve denetlenebilirliği, geliştirme sürecinin ayrılmaz bir parçası olmalıdır.
Bu rehberde, XAI’nin temel kavramlarını, en yaygın kullanılan teknikleri (SHAP ve LIME gibi), uygulama zorluklarını ve pratik kullanım senaryolarını detaylı bir şekilde inceleyeceğiz. Amacımız, makine öğrenimi modellerinizi sadece doğru tahminler yapan araçlar olmaktan çıkarıp, kararlarını açıklayabilen, güvenilir ve etik sistemler haline getirmenize yardımcı olmaktır.
ÖNEMLİ NOKTA
2026 itibarıyla, YZ sistemlerinin “kara kutu” doğası, özellikle kritik uygulamalarda (sağlık, finans) büyük bir sorun teşkil etmektedir. XAI, bu modellerin şeffaflığını artırarak hem etik hem de yasal gereklilikleri karşılamanın anahtarıdır.
TEMEL TEKNİKLER
XAI Teknikleri ve Yaklaşımları: Kara Kutu Modellerini Aydınlatmak
XAI teknikleri, temel olarak iki ana kategoriye ayrılabilir: model-spesifik (belirli bir model türüne özgü) ve model-agnostik (modelden bağımsız, her türlü modele uygulanabilir). Ayrıca, açıklamalar global (modelin genel davranışını açıklayan) veya lokal (tek bir tahminin nedenini açıklayan) olabilir. Bu bölümde, en popüler ve etkili XAI tekniklerinden SHAP ve LIME’ı derinlemesine inceleyeceğiz.
SHAP (SHapley Additive exPlanations)
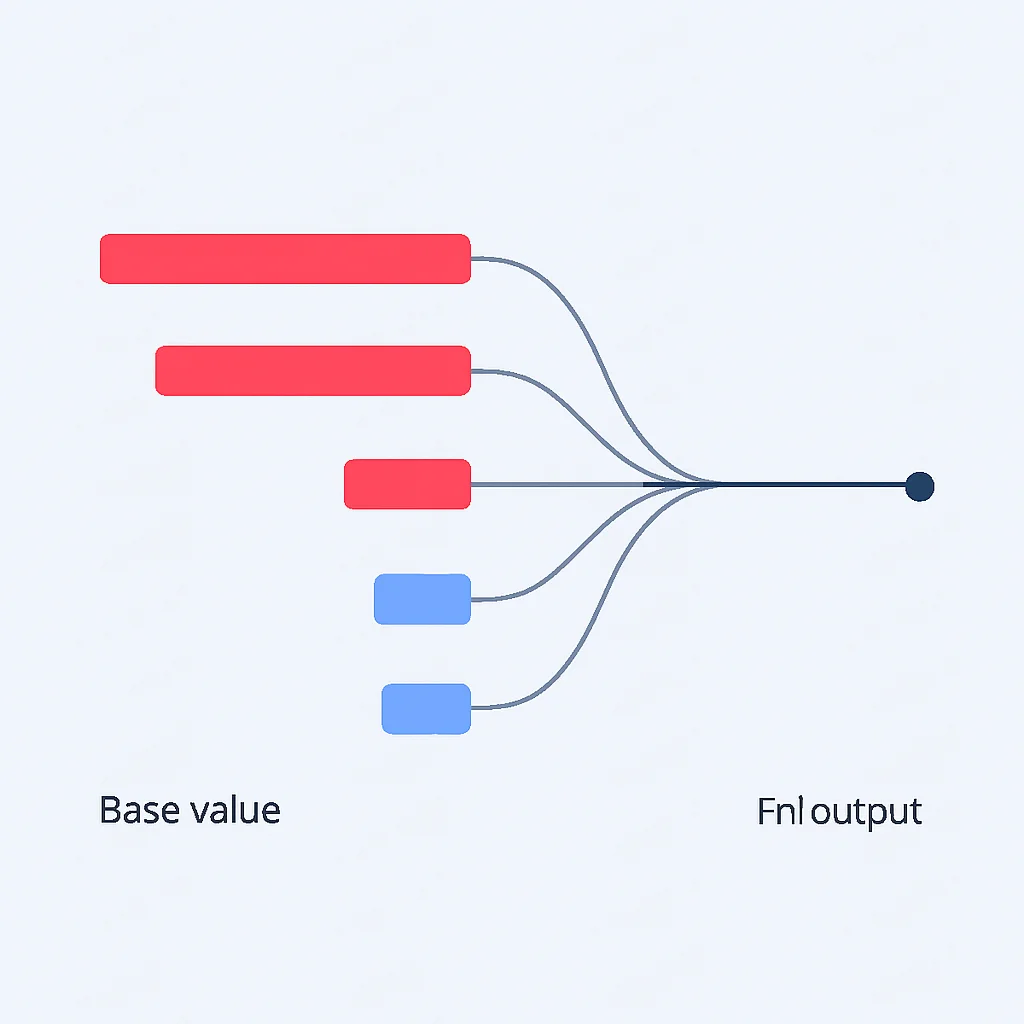
SHAP, oyun teorisinden türetilen Shapley değerleri üzerine kurulu, güçlü bir XAI tekniğidir. Bir modelin tahminindeki her bir özelliğin katkısını adil bir şekilde dağıtarak lokal ve global açıklamalar sunar. Shapley değerleri, bir özelliğin model çıktısına ortalama marjinal katkısını ölçer ve tüm olası özellik kombinasyonları (koalisyonlar) üzerindeki etkisini hesaplar. Bu, SHAP’ı teorik olarak sağlam ve güvenilir bir açıklama yöntemi yapar.
SHAP’ın temel denklemi şu şekildedir: g(z') = ∅0 + ∑j=1M ∅jz'j Burada g açıklanabilir model, z' basitleştirilmiş giriş (ikili), ∅j ise j. özelliğin Shapley değeridir. Bu değer, her bir özelliğin model çıktısına ne kadar “katkıda bulunduğunu” gösterir.
Avantajları:
✓ Teorik Sağlamlık: Oyun teorisine dayanır ve Shapley değerlerinin benzersiz özelliklerini (yerellik, tutarlılık, eksiksizlik) korur.
✓ Lokal ve Global Açıklamalar: Hem tekil tahminlerin nedenlerini hem de modelin genel davranışını açıklayabilir.
✓ Model-Agnostik Yaklaşım: Prensipte herhangi bir makine öğrenimi modeline uygulanabilir (farklı “explainer” türleri ile).
Dezavantajları:
✗ Hesaplama Maliyeti: Tüm özellik kombinasyonlarını değerlendirmek gerektiğinden, özellik sayısı arttıkça hesaplama süresi katlanarak artabilir. Gerçek dünya uygulamalarında genellikle örnekleme veya tahmin yöntemleri kullanılır.
✗ Özellik Bağımlılığı: Bağımlı özellikler olduğunda Shapley değerleri yanlış yorumlanabilir. Bu durum, arka plan veri setinin doğru seçilmesini gerektirir.
KOD AÇIKLAMASI
Aşağıdaki Python kodu, popüler shap kütüphanesini kullanarak bir RandomForestClassifier modelinin tek bir tahmini için Shapley değerlerini hesaplamayı ve görselleştirmeyi göstermektedir. Bu, modelin belirli bir örnek için neden böyle bir karar verdiğini anlamamıza yardımcı olur.
import shap
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# 1. Veri Yükleme ve Hazırlama
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target
# Sadece 2 sınıfı alalım, binary sınıflandırma için
X = X[y != 2]
y = y[y != 2]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. Modeli Eğitme
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 3. SHAP Explainer Oluşturma
# TreeExplainer, ağaç tabanlı modeller için optimize edilmiştir.
explainer = shap.TreeExplainer(model)
# 4. Belirli bir örnek için Shapley değerlerini hesaplama
# Test setindeki ilk örneği seçelim
sample_idx = 0
sample_data = X_test.iloc[[sample_idx]]
shap_values = explainer.shap_values(sample_data)
# Tahmin edilen sınıfın Shapley değerlerini al
# Binary sınıflandırmada, shap_values bir liste olabilir ([shap_values_class0, shap_values_class1])
# Modelin tahmin ettiği sınıfın indeksini alalım
predicted_class = model.predict(sample_data)[0]
# Eğer ikili sınıflandırma ve shap_values bir liste ise
if isinstance(shap_values, list):
shap_values_for_prediction = shap_values[predicted_class]
else:
shap_values_for_prediction = shap_values # Tek çıktılı modeller için
print(f"Örnek {sample_idx} için gerçek sınıf: {y_test.iloc[sample_idx]}")
print(f"Örnek {sample_idx} için model tahmini: {predicted_class}")
print(f"Örnek {sample_idx} için beklenen değer (base value): {explainer.expected_value[predicted_class] if isinstance(explainer.expected_value, np.ndarray) else explainer.expected_value}")
print(f"Örnek {sample_idx} için Shapley değerleri: {shap_values_for_prediction[0]}")
# 5. Sonuçları görselleştirme (force plot)
# shap.initjs() # Jupyter notebook'ta görselleştirmeyi etkinleştirir
# shap.force_plot(explainer.expected_value[predicted_class] if isinstance(explainer.expected_value, np.ndarray) else explainer.expected_value,
# shap_values_for_prediction[0], sample_data)
# Özet plot (global feature importance)
# shap.summary_plot(shap_values[1], X_test) # Sınıf 1 için özet plot
# Bağımlılık plotu (bir özelliğin başka bir özellikle etkileşimini gösterir)
# shap.dependence_plot("petal length (cm)", shap_values[1], X_test, interaction_index="petal width (cm)")
Yukarıdaki kod örneği, bir RandomForestClassifier modelinin tek bir iris çiçeği için sınıflandırma kararını nasıl açıkladığını göstermektedir. shap.TreeExplainer kullanarak, seçilen örneğin özelliklerinin modelin tahminine pozitif veya negatif yönde ne kadar katkıda bulunduğunu sayısal olarak görebiliriz. Örneğin, petal length (cm) özelliğinin yüksek değeri, modelin sınıf 1’i tahmin etmesine büyük katkı sağlarken, sepal width (cm) düşük değeriyle tahminin tersi yönde etki etmiş olabilir.
ÖNEMLİ NOKTA
SHAP değerleri, bir özelliğin model çıktısına olan katkısını adil bir şekilde dağıtarak, özellikle finans ve sağlık gibi yüksek riskli alanlarda modellerin neden belirli kararlar aldığını anlamak için güvenilir bir temel sunar. Ancak, büyük veri setlerinde hesaplama maliyetleri dikkate alınmalıdır.
LIME (Local Interpretable Model-agnostic Explanations)
LIME, “model-agnostik” ve “lokal” açıklamalara odaklanan bir diğer popüler XAI tekniğidir. Temel fikri, açıklamak istediğimiz tek bir tahminin etrafında sentetik veriler oluşturmak ve bu sentetik veriler üzerinde basit, yorumlanabilir bir model (örneğin doğrusal regresyon veya karar ağacı) eğiterek orijinal modelin davranışını yerel olarak yaklaşık olarak açıklamaktır. LIME, modelin genel karmaşıklığına takılmadan, belirli bir örneğe odaklanarak “o an” neden öyle davrandığını anlamamızı sağlar.
LIME algoritması şu adımları izler:
1. Açıklanacak örneği seçin.
2. Seçilen örneğin etrafında (hafifçe değiştirilerek) yeni sentetik veri noktaları oluşturun.
3. Orijinal “kara kutu” modelini kullanarak bu sentetik veri noktalarının tahminlerini alın.
4. Sentetik veri noktalarına, orijinal örneğe olan yakınlıklarına göre ağırlıklar atayın.
5. Ağırlıklı sentetik veriler ve tahminler üzerinde yorumlanabilir bir model (örn. doğrusal model) eğitin. Bu yorumlanabilir model, orijinal modelin yerel davranışının bir vekili olarak hizmet eder.
Avantajları:
✓ Model-Agnostik: Herhangi bir makine öğrenimi modeline uygulanabilir, modelin iç yapısı hakkında bilgi gerektirmez.
✓ Lokal Açıklamalar: Tek bir tahminin nedenini, en etkili özelliklerin bir alt kümesini vurgulayarak açıklar.
✓ Görselleştirmesi Kolay: Özelliklerin tahmin üzerindeki etkisini genellikle pozitif/negatif katkılarla görselleştirmesi kolaydır.
Dezavantajları:
✗ Açıklamaların Kararlılığı: Sentetik veri üretme süreci rastgelelik içerdiğinden, farklı çalıştırmalarda biraz farklı açıklamalar üretebilir.
✗ Komşuluk Tanımı: “Lokal” komşuluğun nasıl tanımlandığı ve sentetik verilerin nasıl üretildiği, açıklamanın kalitesini etkiler.
✗ Genel Model Davranışını Açıklamama: Sadece lokal tahminlere odaklanır, modelin genel davranışını anlamak için birden fazla LIME açıklaması birleştirilmelidir.
KOD AÇIKLAMASI
Bu Python kodu, lime kütüphanesini kullanarak bir RandomForestClassifier modelinin belirli bir tahminini açıklamaktadır. LIME, modelden bağımsız olduğu için, modelin türü ne olursa olsun aynı şekilde kullanılabilir. Kod, bir örneğin tahminini etkileyen en önemli özellikleri ve bunların katkılarını gösterir.
import lime
import lime.lime_tabular
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# 1. Veri Yükleme ve Hazırlama
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target
# Sadece 2 sınıfı alalım, binary sınıflandırma için
X = X[y != 2]
y = y[y != 2]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. Modeli Eğitme
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 3. LIME Explainer Oluşturma
# feature_names: Özellik isimleri
# class_names: Sınıf isimleri
# mode: 'classification' veya 'regression'
explainer = lime.lime_tabular.LimeTabularExplainer(
training_data=X_train.values,
feature_names=X_train.columns.tolist(),
class_names=iris.target_names[y.unique()].tolist(), # Sadece kullanılan sınıfların isimleri
mode='classification'
)
# 4. Belirli bir örnek için LIME açıklaması oluşturma
# Test setindeki ilk örneği seçelim
sample_idx = 0
sample_data_instance = X_test.iloc[sample_idx].values
# Tahmin fonksiyonunu LIME'a uygun hale getirme
# LIME, predict_proba fonksiyonunu bekler
predict_fn = lambda x: model.predict_proba(x)
explanation = explainer.explain_instance(
data_row=sample_data_instance,
predict_fn=predict_fn,
num_features=len(X.columns) # Açıklamada gösterilecek özellik sayısı
)
print(f"Örnek {sample_idx} için gerçek sınıf: {y_test.iloc[sample_idx]}")
print(f"Örnek {sample_idx} için model tahmini: {model.predict(sample_data_instance.reshape(1, -1))[0]}")
print("\nLIME Açıklaması (Özellik, Katkı):")
for feature, weight in explanation.as_list():
print(f"- {feature}: {weight:.4f}")
# 5. Sonuçları görselleştirme (isteğe bağlı, genellikle Jupyter'de)
# explanation.show_in_notebook(show_table=True, show_all=False)
Yukarıdaki LIME örneği, SHAP’a benzer şekilde, bir modelin tek bir tahminini açıklamak için kullanılır. Ancak, LIME’ın yaklaşımı, orijinal modelin etrafında lokal olarak bir vekil model oluşturmaya dayanır. Bu sayede, petal length (cm) gibi özelliklerin, modelin belirli bir iris çiçeğini neden belirli bir sınıfa atadığına dair pozitif veya negatif etkilerini görebiliriz. LIME’ın en büyük gücü, modelin iç işleyişine tamamen bağımsız olmasıdır, bu da onu her türlü “kara kutu” modele uygulanabilir kılar.
ÖNEMLİ NOKTA
LIME, model-agnostik yapısıyla her türlü karmaşık makine öğrenimi modelinin tekil tahminlerini açıklayabilir. Bu esneklik, farklı model mimarilerini kullanan ekipler için büyük bir avantaj sağlar. Ancak, açıklamaların kararlılığı ve komşuluk tanımı, dikkatle ele alınması gereken konulardır.
ZORLUKLAR & ÇÖZÜMLER
XAI Uygulamasındaki Zorluklar ve Çözümler
XAI’nin sağladığı faydalar tartışılmaz olsa da, pratik uygulamada bazı önemli zorluklarla karşılaşılmaktadır. Bu zorlukların üstesinden gelmek, XAI’nin yaygınlaşması ve etkin bir şekilde kullanılması için kritik öneme sahiptir.
SORUN 01
Hesaplama Karmaşıklığı ve Ölçeklenebilirlik
Özellikle SHAP gibi bazı XAI teknikleri, yüksek boyutlu veri setleri ve karmaşık modeller için önemli hesaplama kaynakları gerektirebilir. Milyonlarca veri noktası ve yüzlerce özelliği olan modellerde Shapley değerlerini tam olarak hesaplamak pratik değildir.
ÇÖZÜM — Yaklaşık Hesaplama ve Örnekleme
SHAP ve LIME gibi kütüphaneler, hesaplama maliyetini düşürmek için çeşitli yaklaşık yöntemler ve örnekleme stratejileri sunar. Örneğin, SHAP’ın KernelExplainer veya DeepExplainer gibi varyantları, belirli model türleri için optimize edilmiştir. Ayrıca, açıklama yapılacak veri setini örneklemek veya en önemli özellikleri belirleyip sadece onlar üzerinde açıklama yapmak da performansı artırabilir.
SORUN 02
Yorumlanabilirlik ve Doğruluk Arasındaki Denge
Genellikle, bir model ne kadar karmaşık ve doğru olursa, o kadar az yorumlanabilir olur. Derin sinir ağları gibi yüksek performanslı modeller, genellikle “kara kutu” doğasına sahiptir. Yorumlanabilirliği artırmak, modelin doğruluğundan ödün vermek anlamına gelebilir.
ÇÖZÜM — Model Seçimi ve Post-Hoc Açıklamalar
Bu dengeyi yönetmek için, öncelikle problemin gerektirdiği doğruluk seviyesi ve yorumlanabilirlik ihtiyacı netleştirilmelidir. Eğer yüksek doğruluk kritikse, karmaşık modeller kullanılmalı ve SHAP veya LIME gibi “post-hoc” (model eğitildikten sonra uygulanan) XAI teknikleriyle açıklanmalıdır. Daha düşük doğruluk gerektiren veya doğuştan yorumlanabilir modellerin (örneğin karar ağaçları, doğrusal regresyon) yeterli olduğu durumlarda, bu modeller tercih edilebilir.
SORUN 03
Açıklamaların Yanlış Yorumlanması ve Güven Sorunu
XAI teknikleri tarafından üretilen açıklamalar, uzman olmayan kişiler tarafından yanlış anlaşılabilir veya yanlış yorumlanabilir. Bu durum, YZ sistemlerine olan güveni azaltabilir ve yanlış kararlar alınmasına yol açabilir.
ÇÖZÜM — Kullanıcı Eğitimi ve Bağlamsal Açıklamalar
Kullanıcılara, YZ modellerinin nasıl çalıştığına ve XAI açıklamalarının ne anlama geldiğine dair eğitimler verilmelidir. Açıklamalar, kullanıcının domain bilgisine ve ihtiyacına göre bağlamsallaştırılmalı ve basitleştirilmelidir. Örneğin, bir doktor için tıbbi terimlerle, bir finansçı için finansal terimlerle açıklama sunulabilir. Etkileşimli görselleştirmeler, kullanıcıların açıklamaları daha iyi anlamalarına yardımcı olabilir.
ÖNEMLİ NOKTA
XAI’nin pratik uygulaması, hesaplama verimliliği, doğruluk-yorumlanabilirlik dengesi ve kullanıcı eğitimi gibi çok yönlü zorluklar içerir. Bu zorlukların üstesinden gelmek için teknik yaklaşımların yanı sıra, insan faktörünü ve bağlamı göz önünde bulunduran stratejiler geliştirmek esastır.
UYGULAMA REHBERİ
Pratik Uygulama: XAI ile Model Şeffaflığı Nasıl Artırılır?
XAI tekniklerini makine öğrenimi iş akışınıza entegre etmek, modellerinizin şeffaflığını ve güvenilirliğini önemli ölçüde artırabilir. İşte adım adım bir rehber:
1
İhtiyacı Belirleyin ve Model Seçimi Yapın
Modelinizin neden açıklanması gerektiğini netleştirin (yasal uyumluluk, iş paydaşlarının güveni, hata ayıklama vb.). Projenizin gereksinimlerine göre (doğruluk vs. yorumlanabilirlik) uygun bir makine öğrenimi modeli seçin. Bazı modeller (doğrusal regresyon, karar ağaçları) doğal olarak daha yorumlanabilirdir, ancak karmaşık problemler için derin öğrenme gibi “kara kutu” modeller tercih edilebilir.
2
Veri Hazırlığı ve Model Eğitimi
Modelinizi eğitmek için gerekli veri ön işleme adımlarını uygulayın. Modelinizi eğitin ve performansını değerlendirin. XAI teknikleri, genellikle eğitilmiş bir modelin çıktılarını analiz ettiği için, modelinizin doğru çalıştığından emin olmak önemlidir.
3
Uygun XAI Tekniğini Seçin ve Uygulayın
Modelinizin türüne (ağaç tabanlı, derin öğrenme vb.), açıklama ihtiyacınıza (lokal mi global mi) ve hesaplama kaynaklarınıza göre SHAP, LIME, PDP veya ICE gibi uygun bir XAI tekniği seçin. Örneğin, ağaç tabanlı modeller için shap.TreeExplainer daha verimli olabilirken, herhangi bir model için lime.lime_tabular.LimeTabularExplainer kullanılabilir.
4
Açıklamaları Değerlendirin ve Yorumlayın
Üretilen açıklamaları dikkatlice inceleyin. Özelliklerin model çıktısına etkisini analiz edin. Beklenmedik veya sezgisel olmayan katkılar var mı? Bu durum, veri kalitesi sorunlarına, modeldeki önyargılara veya yanlış özellik mühendisliğine işaret edebilir. Açıklamaları domain uzmanlarıyla paylaşarak geçerliliğini teyit edin.
5
Geri Bildirim Döngüsü ve İyileştirme
XAI açıklamalarından elde edilen içgörüleri kullanarak modelinizi iyileştirin. Örneğin, belirli özelliklerin gereksiz yere yüksek etkiye sahip olduğunu fark ederseniz, bu özellikleri dışarıda bırakmayı veya dönüştürmeyi düşünebilirsiniz. Modeldeki önyargıları tespit ederseniz, veri toplama veya model eğitim stratejilerini ayarlayarak bu önyargıları azaltmaya çalışın. Bu iteratif bir süreçtir.
ÖNEMLİ NOKTA
XAI’yi ML iş akışına entegre etmek, sadece teknik bir uygulama değil, aynı zamanda sürekli bir öğrenme ve iyileştirme sürecidir. Açıklamaları domain uzmanlarıyla paylaşmak, modelin içgörülerinin doğruluğunu ve pratik değerini artırır.
UYGULAMA ALANLARI
Vaka Çalışmaları ve Endüstriyel Uygulamalar
XAI, çeşitli sektörlerde YZ modellerinin güvenilirliğini, şeffaflığını ve kabul edilebilirliğini artırmak için başarıyla kullanılmaktadır. İşte bazı örnekler:
Sağlık Sektörü: Teşhis ve Tedavi Kararları
YZ modelleri, tıbbi görüntü analizi veya hasta verilerine dayanarak hastalıkları teşhis edebilir. XAI, bir modelin neden belirli bir teşhis koyduğunu (örneğin, akciğer röntgeninde belirli bir bölgenin anormalliği nedeniyle) açıklayarak doktorların bu kararlara güvenmesini sağlar ve potansiyel hataları erken aşamada tespit etmelerine yardımcı olur. 2026’da birçok hastane, YZ destekli teşhis sistemlerinde XAI entegrasyonunu zorunlu kılıyor.
Finans Sektörü: Kredi Risk Değerlendirmesi ve Dolandırıcılık Tespiti
Bankalar, YZ modellerini kredi başvurularını değerlendirmek ve dolandırıcılık faaliyetlerini tespit etmek için kullanır. Yasal düzenlemeler (örneğin, GDPR’daki “açıklama hakkı”) gereği, bir kredi başvurusunun neden reddedildiğini açıklamak zorunludur. XAI, bir müşterinin kredi puanını etkileyen faktörleri (gelir, borç geçmişi, ödeme alışkanlıkları) açıkça ortaya koyarak hem müşterilere hem de düzenleyicilere şeffaflık sağlar. Büyük finans kuruluşları, XAI araçlarına yıllık ortalama %15’lik bir yatırım artışı öngörüyor.
Otonom Sistemler: Kendi Kendine Giden Araçlar
Otonom araçlar, karmaşık sensör verilerine dayanarak sürüş kararları alır. Bir kaza durumunda veya beklenmedik bir sürüş manevrası yapıldığında, aracın neden öyle davrandığını açıklayabilmek hayati önem taşır. XAI, aracın kararını etkileyen çevresel faktörleri (yaya tespiti, trafik işareti, yol koşulları) belirleyerek hem mühendislerin hata ayıklamasına hem de yasal soruşturmalara yardımcı olur. 2026’da geliştirilen otonom araç prototiplerinin %80’i XAI bileşenleri içeriyor.
İnsan Kaynakları: İşe Alım ve Performans Değerlendirmesi
YZ destekli işe alım algoritmaları, adayları değerlendirirken önyargı içerebilir. XAI, bir adayın neden reddedildiğini veya tercih edildiğini açıklayarak, algoritmik önyargıları (örneğin, cinsiyet veya etnik köken gibi hassas özelliklere dayalı ayrımcılık) tespit etmeye ve düzeltmeye yardımcı olur. Bu, daha adil ve şeffaf işe alım süreçleri sağlar.
ÖNEMLİ NOKTA
XAI, sektörler arası YZ uygulamalarının güvenilirliğini, şeffaflığını ve etik uygunluğunu artırmak için vazgeçilmez bir araçtır. Özellikle insan hayatını, finansal refahı veya temel hakları etkileyen kararlarda XAI kullanımı, hem yasal uyumluluk hem de toplumsal kabul için kritik öneme sahiptir.
GELECEK