

ÖZET
YOLO ile Gerçek Zamanlı Nesne Algılama: Adım Adım Uygulama Rehberi 2026
YOLO (You Only Look Once) algoritmasını kullanarak gerçek zamanlı nesne algılama modelleri geliştirmek için kapsamlı rehber.
Anahtar Kelimeler: YOLO, Nesne Algılama, Gerçek Zamanlı YZ
İÇİNDEKİLER
1. Giriş: Gerçek Zamanlı Nesne Algılamanın Yükselişi
2. YOLO v8 Mimarisi ve Çalışma Prensibi
3. Veri Seti Hazırlığı ve Etiketleme Süreci
4. Model Eğitimi ve Temel Parametreler
5. Model Değerlendirme ve Optimizasyon Stratejileri
6. Pratik Uygulama: Gerçek Zamanlı Algılama ve Dağıtım
7. Karşılaşılabilecek Zorluklar ve Çözümleri
8. Gelecek Trendler ve YOLO’nun Evrimi
9. Sıkça Sorulan Sorular (SSS)
GİRİŞ
Giriş: Gerçek Zamanlı Nesne Algılamanın Yükselişi
Merhaba Kwontrol okuyucuları! Yapay Zeka ve Makine Öğrenimi dünyasında, bilgisayar görüşü (Computer Vision) alanının en heyecan verici ve pratik uygulamalarından biri olan nesne algılama (Object Detection) konusuyla karşınızdayız. Özellikle son yıllarda, otonom araçlardan güvenlik sistemlerine, perakende analitiğinden tıbbi görüntülemeye kadar pek çok alanda gerçek zamanlı nesne algılamaya olan ihtiyaç katlanarak artmıştır. Bu yazımızda, bu ihtiyaca en etkili yanıtı veren algoritmaların başında gelen YOLO (You Only Look Once) ailesinin en güncel ve güçlü üyesi YOLO v8’i detaylı bir şekilde inceleyeceğiz.
Geleneksel nesne algılama yöntemleri, genellikle iki aşamalı bir süreç izlerdi: önce potansiyel nesne bölgeleri belirlenir, ardından bu bölgeler sınıflandırılırdı. Bu yaklaşım, yüksek doğruluk sunsa da, hesaplama maliyeti ve zaman gecikmesi nedeniyle gerçek zamanlı uygulamalar için yetersiz kalıyordu. İşte tam bu noktada, 2016 yılında Joseph Redmon ve ekibi tarafından tanıtılan YOLO, devrim niteliğinde bir yenilikle sahneye çıktı. YOLO, görüntüyü tek bir ağ geçişinde analiz ederek hem nesnelerin konumunu hem de sınıfını aynı anda tahmin edebilen, “tek atışta” (one-shot) bir algoritmaya dayanır. Bu sayede, hız ve performans açısından büyük bir sıçrama yaşanmıştır.
YOLO serisi, v1’den bugünkü v8’e kadar sürekli olarak gelişti. Her yeni sürüm, daha iyi doğruluk, daha yüksek hız ve daha fazla esneklik sunarak endüstri standartlarını yeniden belirledi. Özellikle 2026 itibarıyla, YOLO v8, mobil cihazlardan bulut tabanlı süper bilgisayarlara kadar geniş bir yelpazede gerçek zamanlı uygulamalar için tercih edilen bir çözüm haline gelmiştir. Bu rehberde, YOLO v8’i kullanarak kendi nesne algılama projenizi sıfırdan nasıl oluşturacağınızı, veri hazırlığından model eğitimine ve dağıtımına kadar adım adım uygulamalı örneklerle açıklayacağız. Bilgisayar görüşü yeteneklerinizi bir sonraki seviyeye taşımaya hazır mısınız?
ÖNEMLİ NOKTA
YOLO, geleneksel iki aşamalı yaklaşımların aksine, nesne algılama sürecini tek bir sinir ağı geçişinde tamamlayarak gerçek zamanlı performansı mümkün kılan devrim niteliğinde bir algoritmadır.
MİMARİ
YOLO v8 Mimarisi ve Çalışma Prensibi
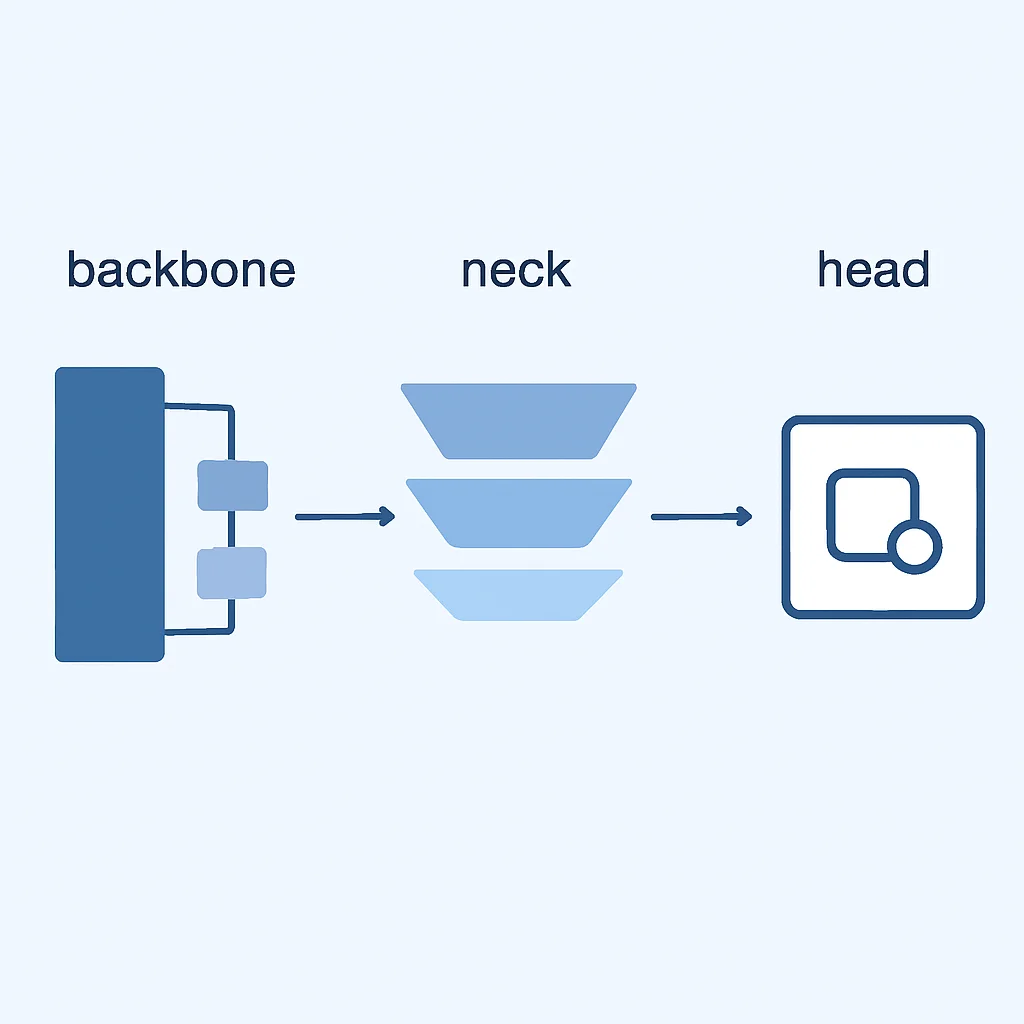
YOLO v8, Ultralytics tarafından geliştirilen ve önceki YOLO modellerinin başarısını temel alarak daha da ileriye taşıyan son teknoloji bir nesne algılama modelidir. Mimari olarak, YOLO ailesinin temel felsefesine sadık kalmakla birlikte, hız ve doğruluk dengesini optimize etmek için bir dizi yenilik sunar. Temel olarak üç ana bileşenden oluşur: Backbone (Omurga), Neck (Boyun) ve Head (Baş).
Backbone (Omurga): Bu kısım, giriş görüntüsünden yüksek seviyeli özellikler çıkarmaktan sorumludur. YOLO v8, önceki versiyonlardaki CSP (Cross Stage Partial) mimarisini daha da optimize ederek, daha verimli ve güçlü bir omurga kullanır. Bu omurga, derin evrişimli katmanlar aracılığıyla görüntünün hiyerarşik temsilini oluşturur. Örneğin, ilk katmanlar kenar ve doku gibi düşük seviyeli özellikleri algılarken, daha derin katmanlar daha karmaşık şekilleri ve nesne parçalarını tanır. Bu sayede, model karmaşık sahnelerdeki nesneleri daha iyi anlayabilir.
Neck (Boyun): Omurgadan çıkarılan farklı ölçeklerdeki özellik haritalarını birleştirerek ve zenginleştirerek algılama için daha uygun hale getirir. YOLO v8, genellikle FPN (Feature Pyramid Network) ve PAN (Path Aggregation Network) gibi yapıları birleştirerek çok ölçekli özellik füzyonu gerçekleştirir. Bu, modelin hem küçük hem de büyük nesneleri etkili bir şekilde algılamasına olanak tanır. Özellikle küçük nesnelerin algılanmasında Neck mimarisinin gücü kritik öneme sahiptir. Örneğin, bir güvenlik kamerasında uzaktaki küçük bir insan figürünü veya bir dron görüntüsünde küçük bir aracı algılamak için bu katmanlar hayati rol oynar.
Head (Baş): Bu kısım, özellik haritalarından nihai algılama kutularını (bounding boxes) ve sınıf olasılıklarını tahmin eder. YOLO v8, “anchor-free” (çapa kutusuz) bir algılama başlığı kullanır. Bu, önceden tanımlanmış çapa kutularına (anchors) ihtiyaç duymadan doğrudan nesne merkezlerini ve boyutlarını tahmin ettiği anlamına gelir. Bu yaklaşım, çapa kutusu ayarlarının manuel olarak yapılmasının getirdiği karmaşıklığı ortadan kaldırır ve modelin genellenebilirliğini artırır. Ayrıca, YOLO v8’de sınıflandırma ve lokalizasyon (nesne konumu tahmini) görevleri için ayrık (decoupled) başlıklar kullanılması, her iki görevin de daha iyi optimize edilmesine ve genel doğrulukta artışa yol açar. Bu ayrım, özellikle karmaşık sahnelerde veya birbirine yakın nesnelerde daha doğru tahminler yapılmasını sağlar.
YOLO v8’in temel avantajları arasında, önceki versiyonlara kıyasla daha yüksek mAP (mean Average Precision) değerleri ve aynı zamanda daha hızlı çıkarım (inference) süreleri bulunur. Örneğin, YOLOv5 ile karşılaştırıldığında, YOLOv8 aynı doğruluk seviyesinde %10-20 daha hızlı çalışabilirken, aynı hızda %5-10 daha yüksek doğruluk sunabilmektedir. Bu optimizasyonlar, modelin mobil cihazlar ve gömülü sistemler gibi kaynak kısıtlı ortamlarda bile etkili bir şekilde çalışmasına olanak tanır. Aşağıdaki görsel, YOLO v8’in genel mimarisini ve veri akışını özetlemektedir.
ÖNEMLİ NOKTA
YOLO v8’in “anchor-free” ve “decoupled head” mimarisi, modelin daha esnek, daha doğru ve daha kolay optimize edilebilir olmasını sağlayarak önceki versiyonlara göre önemli bir avantaj sunar.
VERİ HAZIRLIĞI
Veri Seti Hazırlığı ve Etiketleme Süreci
Her başarılı derin öğrenme projesinin temelinde, yüksek kaliteli ve iyi hazırlanmış bir veri seti yatar. Nesne algılama modelleri için de durum farklı değildir. Modelinizin ne kadar iyi performans göstereceği, büyük ölçüde ona sunduğunuz verilerin çeşitliliğine, doğruluğuna ve büyüklüğüne bağlıdır. Bu bölümde, YOLO v8 için veri seti hazırlığı ve etiketleme sürecinin kritik adımlarını inceleyeceğiz.
1. Görüntü Toplama
İlk adım, modelinizin algılamasını istediğiniz nesneleri içeren yeterli sayıda görüntü toplamaktır. Bu görüntüler, nesnelerin farklı açılardan, farklı aydınlatma koşullarında, farklı arka planlarda ve farklı ölçeklerde görünmesini sağlamalıdır. Örneğin, bir “araba” algılama modeli için, sadece güneşli havada çekilmiş görüntüler değil, yağmurlu, karlı, gece ve gündüz çekilmiş görüntüler de olmalıdır. Minimum 500-1000 görüntü ile başlamak iyi bir başlangıç noktası olabilir, ancak daha iyi performans için binlerce görüntüye ihtiyaç duyulabilir. Görüntüleri kendi kameralarınızla çekebilir, herkese açık veri setlerinden (örneğin, Open Images Dataset) yararlanabilir veya web’den veri kazıma (web scraping) yöntemlerini kullanabilirsiniz.
2. Görüntü Etiketleme (Annotation)
Görüntüleri topladıktan sonra, her bir görüntüdeki hedef nesnelerin konumunu ve sınıfını manuel olarak işaretlemeniz gerekir. Bu sürece etiketleme veya anotasyon denir. Nesne algılama için genellikle “sınırlayıcı kutular” (bounding boxes) kullanılır. Popüler etiketleme araçları şunlardır:
- LabelImg: Açık kaynaklı, kullanımı kolay bir masaüstü uygulamasıdır. Hem Pascal VOC (XML) hem de YOLO (TXT) formatlarında etiketleme yapabilir.
- Roboflow: Bulut tabanlı bir platformdur. Etiketleme, veri artırma, format dönüştürme ve model dağıtımı gibi birçok özelliği bir arada sunar. Özellikle büyük projeler ve ekip çalışmaları için idealdir.
- CVAT (Computer Vision Annotation Tool): Intel tarafından geliştirilen, güçlü ve esnek bir web tabanlı etiketleme aracıdır.
YOLO formatında etiketleme yaparken, her görüntü için bir .txt dosyası oluşturulur ve bu dosya görüntüyle aynı ada sahip olur. Her satır, bir nesneyi temsil eder ve şu formatı izler: [class_id] [center_x] [center_y] [width] [height]. Tüm koordinatlar, görüntünün genişliği ve yüksekliğine göre normalleştirilmiş (0 ile 1 arasında) değerlerdir. class_id ise 0’dan başlayan tam sayıdır.
KOD AÇIKLAMASI
Aşağıdaki kod bloğu, bir YOLO etiketleme dosyasının içeriğini göstermektedir. Burada ‘0’ sınıf id’si, ‘0.5000’ ve ‘0.4500’ nesnenin merkez noktasının x ve y koordinatlarının normalleştirilmiş değerleri, ‘0.2000’ ve ‘0.3000’ ise nesnenin genişlik ve yüksekliğinin normalleştirilmiş değerleridir.
# Resim: image001.jpg
# Etiket dosyası: image001.txt
# İçerik:
# class_id center_x center_y width height
0 0.5000 0.4500 0.2000 0.3000
1 0.2500 0.7000 0.1500 0.1000
0 0.8000 0.2000 0.1800 0.2500Bu örnekte, ‘0’ sınıfına ait iki nesne ve ‘1’ sınıfına ait bir nesne bulunmaktadır. Sınıf id’leri, data.yaml dosyasında tanımlanan sınıf isimlerine karşılık gelir.
3. Veri Artırma (Data Augmentation)
Topladığınız görüntü sayısı yetersizse veya modelinizin genelleme yeteneğini artırmak istiyorsanız, veri artırma teknikleri kullanabilirsiniz. Veri artırma, mevcut görüntüler üzerinde rastgele dönüşümler (döndürme, çevirme, parlaklık/kontrast ayarı, kırpma, gürültü ekleme vb.) uygulayarak yeni eğitim örnekleri oluşturma işlemidir. Bu, modelin farklı varyasyonlara karşı daha sağlam olmasını sağlar ve aşırı öğrenmeyi (overfitting) azaltır. YOLO v8, eğitim sırasında otomatik olarak çeşitli veri artırma tekniklerini (örneğin, mosaic, mixup) uygular, ancak Roboflow gibi araçlarla manuel olarak da uygulayabilirsiniz.
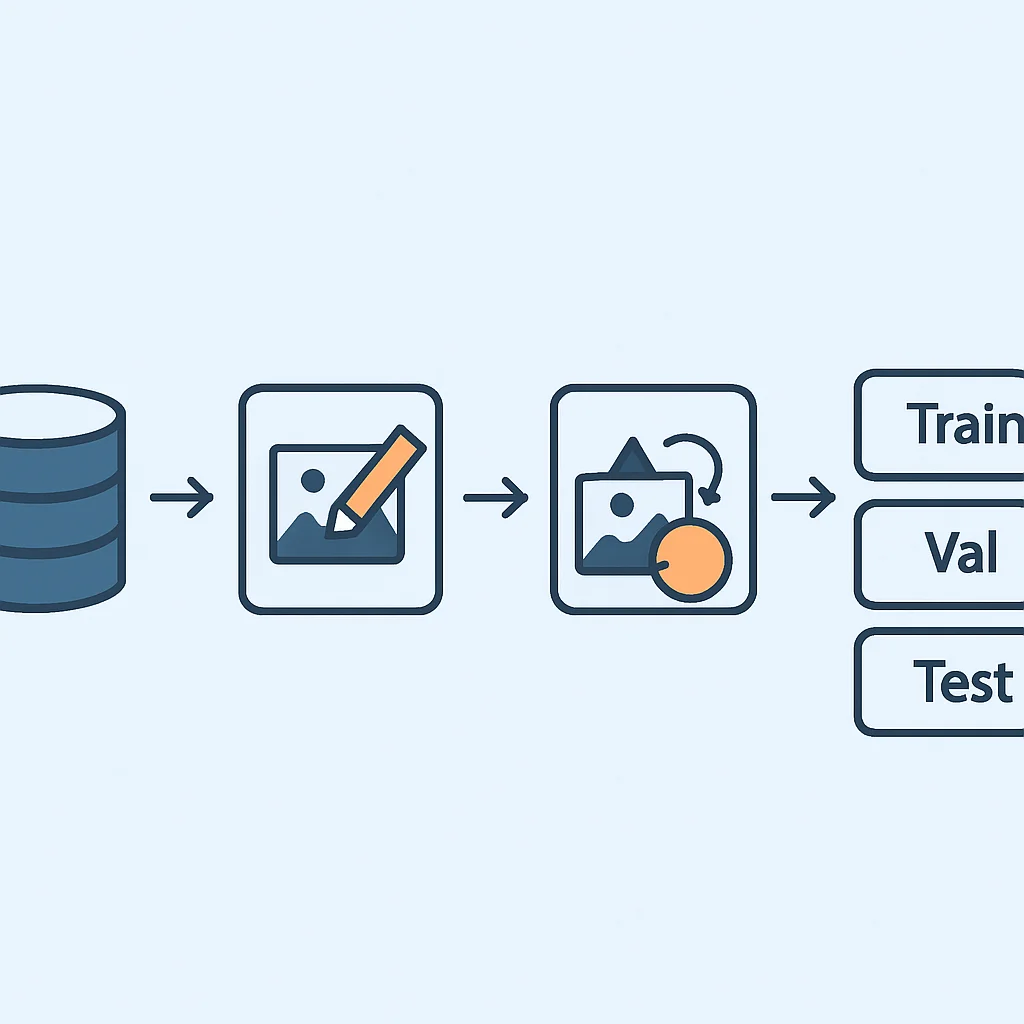
4. Veri Seti Bölme
Veri setinizi genellikle üç ana bölüme ayırmanız gerekir:
- Eğitim Seti (Training Set): Modelin öğrenmesi için kullanılan ana veri kümesidir (genellikle %70-80).
- Doğrulama Seti (Validation Set): Eğitim sırasında modelin performansını izlemek ve hiperparametreleri ayarlamak için kullanılır (genellikle %10-15). Model bu verilerle eğitilmez.
- Test Seti (Test Set): Modelin nihai, bağımsız performansını değerlendirmek için kullanılır (genellikle %10-15). Model bu verileri eğitim veya doğrulama sırasında hiç görmemiştir.
Bu bölme işlemi, modelinizin yeni, daha önce görmediği verilere ne kadar iyi genelleme yapabildiğini anlamak için kritik öneme sahiptir. Aşağıdaki görsel, örnek bir veri setinin etiketleme sonrası ve eğitim öncesi yapısını göstermektedir.
ÖNEMLİ NOKTA
Yüksek kaliteli ve çeşitli bir veri seti, modelinizin gerçek dünya senaryolarında iyi performans göstermesi için temeldir. Etiketleme doğruluğu ve veri artırma teknikleri, model performansını doğrudan etkiler.
MODEL EĞİTİMİ
Model Eğitimi ve Temel Parametreler
Veri setiniz hazırlandıktan ve etiketlendikten sonra, sıra modelinizi eğitmeye gelir. YOLO v8, hem yeni bir model sıfırdan eğitmeyi hem de önceden eğitilmiş bir modeli (pre-trained model) kendi verilerinizle ince ayar yapmayı (fine-tuning) kolaylaştırır. Genellikle, büyük bir veri seti üzerinde eğitilmiş önceden eğitilmiş bir modelle başlamak, daha hızlı ve daha iyi sonuçlar verir, çünkü bu modeller genel özellik çıkarma yeteneğini zaten kazanmıştır.
1. Gerekli Donanım ve Ortam Kurulumu
Derin öğrenme modelleri, özellikle nesne algılama gibi görsel görevler, yoğun hesaplama gerektirir. Bu nedenle, bir GPU (Graphics Processing Unit) kullanmak neredeyse zorunludur. NVIDIA GPU’lar (örneğin, RTX 3080, A100) ve CUDA, cuDNN gibi kütüphaneler, eğitim sürecini önemli ölçüde hızlandırır. CPU üzerinde eğitim yapmak, günler hatta haftalar sürebilirken, bir GPU ile aynı eğitim saatler içinde tamamlanabilir. Ayrıca, Python ve ultralytics kütüphanesini kurmanız gerekecektir:
KOD AÇIKLAMASI
YOLO v8’i kullanmak için gerekli Python kütüphanesini ve bağımlılıklarını kurma komutları. Sanal ortam kullanılması şiddetle tavsiye edilir.
# Sanal ortam oluşturma ve etkinleştirme
python -m venv yolov8_env
source yolov8_env/bin/activate # Linux/macOS
# yolov8_env\Scripts\activate # Windows
# Ultralytics kütüphanesini kurma
pip install ultralytics
# Gerekli diğer kütüphaneleri kurma (örneğin, OpenCV)
pip install opencv-python numpy2. Veri Yapılandırması (data.yaml)
YOLO v8, veri setinizin konumunu ve sınıf bilgilerini içeren bir .yaml dosyası bekler. Bu dosya, eğitim ve doğrulama görüntüleri ile etiketlerinin yollarını, ayrıca algılayacağınız nesne sınıflarının sayısını ve isimlerini tanımlar.
KOD AÇIKLAMASI
Örnek bir data.yaml dosyası. train ve val yolları, görüntülerin bulunduğu dizinleri gösterir. nc sınıf sayısı, names ise sınıf isimleridir.
# data.yaml
train: /path/to/your/dataset/images/train/
val: /path/to/your/dataset/images/val/
nc: 2 # Number of classes
names: ['car', 'person'] # Class names3. Eğitim Parametreleri
Eğitim sürecini kontrol eden birkaç önemli hiperparametre vardır:
epochs: Modelin tüm eğitim veri setini kaç kez göreceğini belirler. Daha fazla epoch, genellikle daha iyi öğrenme anlamına gelir ancak aşırı öğrenmeye yol açabilir. Genellikle 100-500 epoch arasında bir değerle başlanır.batch_size: Her eğitim adımında işlenecek görüntü sayısıdır. Daha büyük batch size, daha hızlı eğitim süresi ve daha kararlı gradyanlar sağlayabilir, ancak daha fazla GPU belleği gerektirir. Tipik değerler 16, 32, 64’tür.imgsz: Giriş görüntülerinin piksel cinsinden boyutu. YOLO v8 genellikle 640×640 boyutunda görüntülerle eğitilir, ancak daha yüksek çözünürlük (örneğin, 1280×1280) daha iyi doğruluk sağlayabilirken, daha yavaş çıkarım süresine yol açar.model: Kullanılacak YOLO v8 modelinin boyutu/türü (örneğin,yolov8n.pt(nano),yolov8s.pt(small),yolov8m.pt(medium) vb.). Daha büyük modeller daha doğru ancak daha yavaştır.pretrained: Önceden eğitilmiş ağırlıkların kullanılıp kullanılmayacağını belirtir. GenellikleTrueolarak ayarlanır.
4. Eğitim Komutu
YOLO v8’i eğitmek için ultralytics kütüphanesi basit bir CLI (Command Line Interface) veya Python API sunar.
KOD AÇIKLAMASI
Örnek bir Python betiği kullanarak YOLO v8 modelini eğitme komutu. yolov8s.pt önceden eğitilmiş küçük bir modeldir. Kendi data.yaml dosyanızın yolunu belirtmeyi unutmayın.
from ultralytics import YOLO
# Bir YOLOv8s modelini yükle (small model)
model = YOLO('yolov8s.pt')
# Modeli özel veri setiniz üzerinde eğitin
results = model.train(data='data.yaml', epochs=100, imgsz=640, batch=16, name='yolov8_custom_detector')
print("Eğitim tamamlandı!")Eğitim sırasında, modelin performansını gösteren çeşitli metrikler konsolda ve kaydedilen log dosyalarında gösterilecektir. Bu metrikler arasında hassasiyet (Precision), hatırlama (Recall) ve ortalama hassasiyet (mAP – mean Average Precision) bulunur. Özellikle [email protected] ve [email protected]:0.95 değerleri, modelin nesneleri ne kadar doğru ve güvenilir bir şekilde algıladığını gösterir. [email protected], %50 IOU (Intersection Over Union) eşiğinde ortalama hassasiyeti ifade ederken, [email protected]:0.95 farklı IOU eşiklerinde (0.5’ten 0.95’e kadar 0.05’lik adımlarla) ortalama hassasiyetin ortalamasıdır ve daha kapsamlı bir değerlendirme sunar.
ÖNEMLİ NOKTA
Etkili bir model eğitimi için GPU kullanımı şarttır. Önceden eğitilmiş modellerle başlamak (transfer öğrenimi) ve doğru hiperparametreleri (epochs, batch_size, imgsz) seçmek, başarılı sonuçlar elde etmenin anahtarıdır.
DEĞERLENDİRME
Model Değerlendirme ve Optimizasyon Stratejileri
Model eğitimi tamamlandıktan sonra, modelin ne kadar iyi performans gösterdiğini anlamak için kapsamlı bir değerlendirme yapmak ve gerekirse iyileştirmeler için optimizasyon stratejileri uygulamak önemlidir. Bu bölüm, model performansını analiz etme ve optimize etme yöntemlerini ele alacaktır.
1. Model Performans Metrikleri
Nesne algılama modellerinin performansını değerlendirmek için kullanılan başlıca metrikler şunlardır:
- Precision (Hassasiyet): Modelin doğru pozitif olarak tahmin ettiği nesnelerin, tüm pozitif tahminlerine oranıdır. Yüksek hassasiyet, yanlış pozitiflerin (modelin bir nesne olduğunu düşündüğü ancak aslında olmayan) az olduğunu gösterir.
- Recall (Hatırlama): Tüm gerçek pozitif nesnelerin, model tarafından doğru pozitif olarak algılananlara oranıdır. Yüksek hatırlama, modelin çoğu gerçek nesneyi kaçırmadığını gösterir.
- mAP (mean Average Precision): Hassasiyet-hatırlama eğrisinin altındaki alanın ortalamasıdır. Hem hassasiyet hem de hatırlamayı tek bir değerde özetler. [email protected] ve [email protected]:0.95 gibi farklı IOU eşiklerinde hesaplanır. YOLO v8 projelerinde en kritik metriklerden biridir.
- FPS (Frames Per Second): Modelin bir saniyede kaç görüntü işleyebildiğini gösterir. Gerçek zamanlı uygulamalar için bu metrik hayati öneme sahiptir.
Eğitim sonrası, model.val() komutu ile doğrulama seti üzerinde model performansını detaylı olarak ölçebilirsiniz. Bu, size her sınıf için ayrı ayrı ve genel mAP değerlerini sağlayacaktır.
2. Optimizasyon Stratejileri
Eğer modelinizin performansı beklentilerinizi karşılamıyorsa, uygulayabileceğiniz bazı optimizasyon stratejileri vardır:
- Hiperparametre Ayarı (Hyperparameter Tuning): Öğrenme oranı (learning rate), epoch sayısı, batch boyutu, optimizasyon algoritması (SGD, Adam vb.) gibi parametreleri değiştirerek model performansını etkileyebilirsiniz. Otomatik hiperparametre optimizasyonu için Ray Tune veya Optuna gibi kütüphaneler kullanılabilir.
- Veri Artırma Stratejilerini Geliştirme: Daha agresif veya farklı veri artırma teknikleri (CutMix, Copy-Paste) kullanarak modelin genelleme yeteneğini artırabilirsiniz.
- Daha Fazla/Daha Kaliteli Veri: Modelin en büyük performans artışı genellikle daha fazla ve daha çeşitli eğitim verisi eklemekten gelir. Özellikle modelin zorlandığı durumlardaki örnekleri veri setinize dahil etmek önemlidir. Örneğin, düşük ışıkta veya kısmen gizlenmiş nesnelerle ilgili daha fazla görüntü eklemek.
- Model Boyutunu Değiştirme: Daha büyük bir YOLO v8 modeli (örneğin,
yolov8l.ptveyayolov8x.pt) kullanmak, genellikle daha iyi doğruluk sağlar ancak daha fazla hesaplama kaynağı gerektirir. - Transfer Öğrenimi ve İnce Ayar: Eğer çok az veriniz varsa, büyük bir veri seti üzerinde (örneğin COCO) eğitilmiş bir YOLO v8 modelini alıp, kendi küçük veri setiniz üzerinde sadece son katmanlarını veya tüm modelini daha düşük bir öğrenme oranıyla eğitmek (ince ayar), sıfırdan eğitime göre çok daha iyi sonuçlar verebilir.
Model değerlendirme sonuçlarını görselleştirmek için TensorBoard veya Weights & Biases gibi araçları kullanmak, eğitim sürecini ve metriklerin değişimini grafikler halinde izlemenize olanak tanır. Bu sayede, modelin aşırı öğrenip öğrenmediğini veya daha fazla eğitime ihtiyacı olup olmadığını kolayca anlayabilirsiniz. Aşağıdaki görsel, örnek bir mAP ve kayıp (loss) grafiğini temsil etmektedir.
ÖNEMLİ NOKTA
mAP, Precision, Recall ve FPS gibi metrikleri dikkatlice inceleyerek modelinizin güçlü ve zayıf yönlerini belirleyin. Hiperparametre ayarı ve veri setini zenginleştirme, model optimizasyonunda en etkili adımlardır.
UYGULAMA
Pratik Uygulama: Gerçek Zamanlı Algılama ve Dağıtım
Modelinizi başarıyla eğittikten ve optimize ettikten sonra, sıra onu gerçek dünya senaryolarında kullanmaya gelir. YOLO v8’in en büyük avantajlarından biri, gerçek zamanlı çıkarım (inference) yeteneğidir. Bu bölümde, eğitilmiş modelinizi kullanarak görüntüler, videolar veya canlı kamera akışları üzerinde nesne algılama yapmayı ve dağıtım seçeneklerini inceleyeceğiz.
1. Görüntüler ve Videolar Üzerinde Çıkarım
Eğitilmiş .pt dosyanızı kullanarak tek bir görüntü, bir klasör dolusu görüntü veya bir video dosyası üzerinde algılama yapabilirsiniz. ultralytics kütüphanesi bunu son derece basit hale getirir.
KOD AÇIKLAMASI
Eğitilmiş YOLO v8 modelini kullanarak bir görüntü ve bir video üzerinde nesne algılama gerçekleştiren Python kodu. model.predict() fonksiyonu, algılanan nesneleri sınırlayıcı kutular ve güven skorlarıyla birlikte döndürür.
from ultralytics import YOLO
# Eğitilmiş modelinizi yükleyin
model = YOLO('runs/detect/yolov8_custom_detector/weights/best.pt') # Kendi model yolunuzu belirtin
# Tek bir görüntü üzerinde algılama yapın
results_image = model.predict(source='path/to/your/image.jpg', save=True, conf=0.5)
# Bir video üzerinde algılama yapın
results_video = model.predict(source='path/to/your/video.mp4', save=True, conf=0.5)
# Canlı kamera akışı üzerinde algılama yapın (webcam id 0)
# results_webcam = model.predict(source=0, save=True, conf=0.5)
print("Algılama tamamlandı. Sonuçlar 'runs/detect' klasöründe kaydedildi.")Yukarıdaki kodda, save=True parametresi, sonuçların (algılanan nesnelerle işaretlenmiş görüntüler/videolar) otomatik olarak runs/detect klasörüne kaydedilmesini sağlar. conf=0.5 ise güven eşiğini belirler; yalnızca %50’den daha yüksek güvenle algılanan nesneler gösterilir.
2. Gerçek Zamanlı Kamera Akışı Üzerinde Uygulama
YOLO v8’in gerçek potansiyeli, canlı kamera akışları üzerinde nesneleri gerçek zamanlı olarak algılama yeteneğinde yatar. Bu, güvenlik kameraları, endüstriyel otomasyon ve otonom robotlar gibi birçok alanda kritik öneme sahiptir.
Kullanım Örneği: Akıllı Güvenlik Kamerası
Bir fabrika veya depoda, izinsiz girişleri veya tehlikeli bölgelere yaklaşan insanları tespit etmek için YOLO v8 tabanlı bir akıllı güvenlik kamerası sistemi kurulabilir. Sistem, canlı kamera akışını analiz eder, şüpheli hareketleri algılar ve anında güvenlik personeline bildirim gönderir. Bu, hem güvenlik ihlallerini önler hem de olaylara müdahale süresini kısaltır.
Canlı akış üzerinde algılama yapmak için yukarıdaki kodda source=0 (dahili kamera için) veya IP kamera adresi gibi bir kaynak belirtmeniz yeterlidir. Model, her kareyi işleyecek ve algılanan nesneleri ekranda gösterecektir. Performans, kullanılan GPU’nun gücüne ve modelin boyutuna bağlı olarak saniyede 30-100+ kare (FPS) arasında değişebilir.
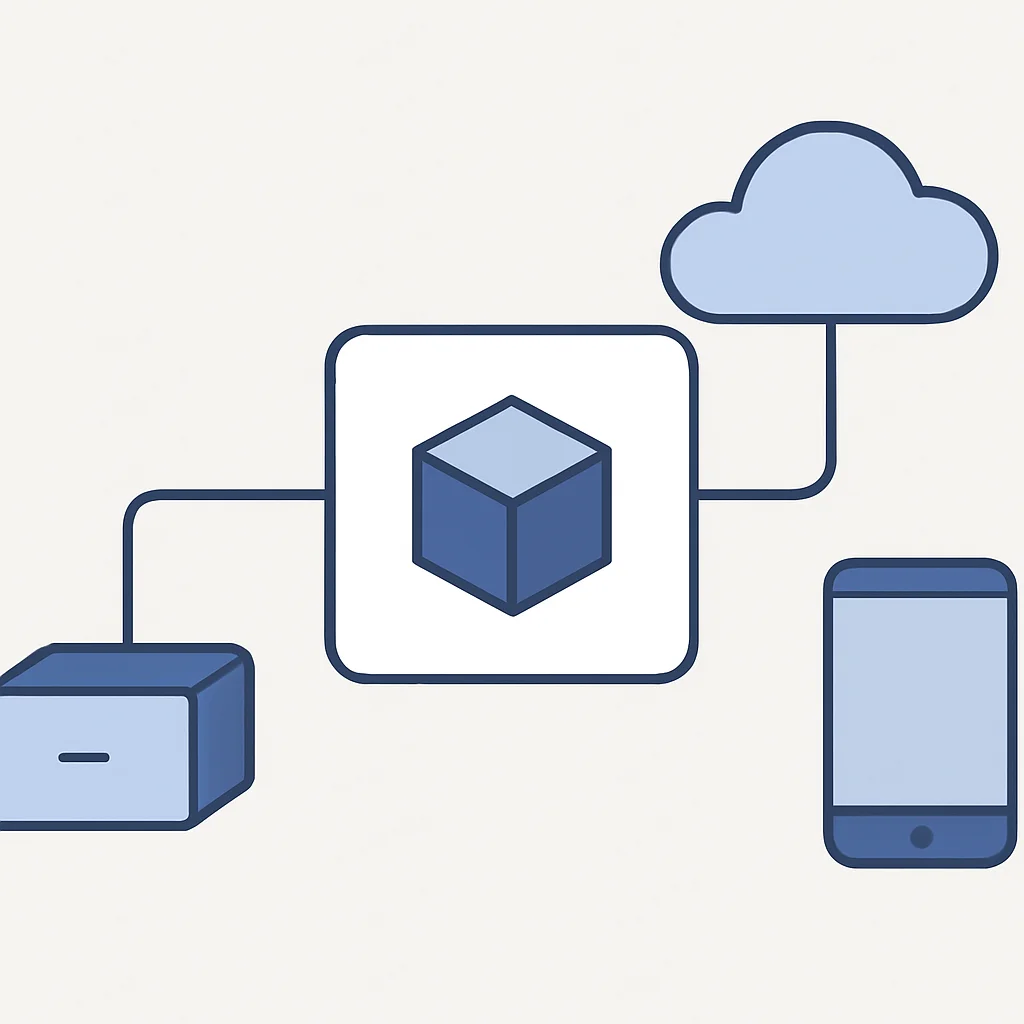
3. Model Dağıtımı (Deployment)
Eğitilmiş modelinizi bir uygulamaya veya ürüne entegre etmek, dağıtım sürecini kapsar. YOLO v8, çeşitli dağıtım formatlarını destekler:
- PyTorch (
.pt): Doğrudan Python uygulamalarınızda kullanabileceğiniz varsayılan formattır. - ONNX (Open Neural Network Exchange): Farklı derin öğrenme çerçeveleri arasında model transferi için standart bir formattır. Performans optimizasyonu için kullanılabilir.
- TensorRT: NVIDIA GPU’lar üzerinde en yüksek çıkarım performansını elde etmek için tasarlanmış bir optimizasyon motorudur. Özellikle düşük gecikme süresi gerektiren gerçek zamanlı uygulamalar için idealdir.
- OpenVINO: Intel donanımları üzerinde çıkarımı optimize etmek için kullanılan bir araç takımıdır.
- TFLite/Core ML: Mobil cihazlar (Android/iOS) üzerinde dağıtım için hafifletilmiş formatlardır.
Modelinizi farklı formatlara dönüştürmek için model.export() fonksiyonunu kullanabilirsiniz. Örneğin, model.export(format='onnx') komutu, modelinizi ONNX formatına dönüştürecektir. Dağıtım platformunuza uygun formatı seçmek, performansı ve uyumluluğu artırır. Aşağıdaki görsel, farklı dağıtım hedeflerini göstermektedir.
ÖNEMLİ NOKTA
YOLO v8, model.predict() fonksiyonu ile görüntü, video ve canlı akışlarda kolayca gerçek zamanlı algılama yapabilir. Dağıtım için modelinizi platformunuza uygun formatlara dönüştürmek performansı artırır.
ZORLUKLAR
Karşılaşılabilecek Zorluklar ve Çözümleri
YOLO v8 ile nesne algılama projeleri geliştirirken, her teknolojik girişimde olduğu gibi bazı zorluklarla karşılaşmanız olasıdır. Bu zorlukları önceden bilmek ve olası çözümlerini anlamak, proje sürecinizi daha verimli hale getirecektir.
SORUN 01
Yetersiz veya Dengesiz Veri Seti
Modelin doğru ve güvenilir tahminler yapabilmesi için yeterli miktarda ve çeşitli veri setine ihtiyaç vardır. Eğer veri setiniz küçükse veya belirli sınıflar diğerlerinden çok daha az örneğe sahipse (sınıf dengesizliği), modelin performansı ciddi şekilde düşebilir.
ÇÖZÜM — Veri Artırma ve Toplama
1. Veri Artırma (Data Augmentation): Mevcut görüntüler üzerinde rastgele döndürme, çevirme, kırpma, parlaklık ve kontrast ayarı gibi dönüşümler uygulayarak veri setinizi sentetik olarak genişletin. YOLO v8’in kendi içinde sunduğu mosaic ve mixup gibi gelişmiş artırma tekniklerini kullanın.
2. Daha Fazla Veri Toplama: Mümkünse, modelin zorlandığı senaryoları içeren ek görüntüler toplayın ve etiketleyin. Özellikle az temsil edilen sınıflar için bu hayati öneme sahiptir.
SORUN 02
Aşırı Öğrenme (Overfitting) veya Yetersiz Öğrenme (Underfitting)
Aşırı öğrenme, modelin eğitim verisini ezberlemesi ancak yeni verilere genelleme yapamaması durumudur. Yetersiz öğrenme ise modelin eğitim verisindeki kalıpları yeterince öğrenememesidir.
ÇÖZÜM — Hiperparametre Ayarı ve Düzenlileştirme
1. Erken Durdurma (Early Stopping): Doğrulama seti üzerindeki performans düşmeye başladığında eğitimi durdurun. Bu, aşırı öğrenmeyi önlemenin en basit yollarından biridir.
2. Düzenlileştirme (Regularization): Ağırlık azaltma (weight decay) gibi teknikler, modelin karmaşıklığını azaltarak aşırı öğrenmeyi önler. YOLO v8’in eğitim parametrelerinde bu ayarlar mevcuttur.
3. Öğrenme Oranı Ayarı: Çok yüksek öğrenme oranı yetersiz öğrenmeye, çok düşük öğrenme oranı ise yavaş öğrenmeye veya yerel minimumlara takılmaya yol açabilir. Optimal bir öğrenme oranı bulmak için denemeler yapın.
SORUN 03
Hesaplama Kaynakları ve Hız Kısıtlamaları
Gerçek zamanlı nesne algılama, özellikle yüksek çözünürlüklü görüntüler veya yüksek FPS gerektiren uygulamalar için önemli miktarda işlem gücü (GPU) gerektirebilir. Kaynak kısıtlı ortamlarda (örneğin, gömülü sistemler) performans düşüşleri yaşanabilir.
ÇÖZÜM — Model Optimizasyonu ve Donanım Seçimi
1. Daha Küçük Model Kullanımı: YOLO v8’in ‘nano’ (yolov8n.pt) veya ‘small’ (yolov8s.pt) gibi daha hafif versiyonlarını kullanın. Bunlar, doğruluktan biraz ödün vererek önemli ölçüde daha hızlı çalışır.
2. Model Kuantizasyonu ve Budama (Pruning): Modelin boyutunu ve hesaplama yükünü azaltmak için kuantizasyon (ağırlıkları daha düşük bit derinliğine dönüştürme) veya budama (önemsiz bağlantıları kaldırma) tekniklerini uygulayın.
3. Donanım Hızlandırma: NVIDIA TensorRT veya Intel OpenVINO gibi araçları kullanarak çıkarım performansını optimize edin. Gerekirse, daha güçlü bir GPU’ya yatırım yapın veya bulut tabanlı GPU hizmetlerini (AWS, GCP, Azure) kullanın.
4. Giriş Görüntüsü Boyutu: Giriş görüntüsü boyutunu (imgsz) düşürmek, çıkarım hızını artırabilir ancak küçük nesnelerin algılanmasında doğruluk kaybına yol açabilir.
ÖNEMLİ NOKTA
Veri kalitesi, aşırı/yetersiz öğrenme ve hesaplama kaynakları, YOLO projelerinde sıkça karşılaşılan zorluklardır. Bu sorunlara karşı veri artırma, hiperparametre ayarı ve model optimizasyonu gibi çözümler uygulanabilir.
GELECEK
Gelecek Trendler ve YOLO’nun Evrimi
Yapay zeka ve makine öğrenimi alanı, her geçen gün inanılmaz bir hızla gelişmeye devam ediyor. YOLO gibi algoritmalar, bu gelişmelerin ön saflarında yer alarak bilgisayar görüşü yeteneklerimizi sürekli olarak ileriye taşıyor. 2026 ve sonrası için nesne algılamanın geleceğine dair bazı önemli trendler ve YOLO ailesinin bu evrimdeki rolü şunlardır:
1. Daha Büyük ve Genel Modeller (Foundation Models)
Doğal Dil İşleme’deki (NLP) büyük dil modellerine benzer şekilde, bilgisayar görüşünde de çok büyük ve genel “temel modeller” (foundation models) geliştirilmektedir. Bu modeller, devasa, etiketlenmemiş veri setleri üzerinde eğitilir ve daha sonra belirli görevlere (nesne algılama, segmentasyon vb.) uyarlanabilirler. Gelecekteki YOLO versiyonları, bu tür temel modellerin yeteneklerini entegre ederek, çok daha az etiketli veriyle bile üstün performans gösterebilir.
2. Multimodal Yapay Zeka
Yalnızca görsel verilere değil, aynı zamanda metin, ses, radar veya lidar gibi farklı sensörlerden gelen bilgilere dayalı nesne algılama sistemleri daha yaygın hale gelecektir. Örneğin, bir otonom araç, kameradan gelen görsel veriyi, radardan gelen mesafe bilgisini ve hatta çevresel sesleri birleştirerek daha doğru ve sağlam algılama yapabilir. YOLO tabanlı modeller, bu multimodal veri füzyonunu destekleyecek şekilde evrilecektir.
3. Daha Verimli ve Hafif Modeller
Edge cihazlarda (mobil telefonlar, dronlar, IoT cihazları) yapay zeka uygulamalarının artmasıyla birlikte, daha az hesaplama gücü ve bellek tüketen ancak yüksek doğruluk sağlayan “hafif” modellerin geliştirilmesine odaklanılacaktır. YOLO serisi, her yeni versiyonunda bu verimlilik hedefini gözetmiştir ve bu trendin devam etmesi beklenmektedir. Örneğin, YOLO v8’in farklı boyutlardaki modelleri (n, s, m, l, x) bu ihtiyaca yanıt vermektedir.
4. Etik ve Şeffaf Yapay Zeka
Yapay zeka sistemlerinin toplum üzerindeki etkisi arttıkça, etik konular ve model şeffaflığı daha fazla önem kazanacaktır. Nesne algılama modellerinin önyargıları (bias) azaltması, kararlarının daha açıklanabilir olması (XAI – Explainable AI) ve gizlilik endişelerini gidermesi için yeni yaklaşımlar geliştirilecektir. YOLO topluluğu da bu etik standartlara uyum sağlamak için çalışmalar yürütecektir.
YOLO v8, bu heyecan verici geleceğe doğru atılmış önemli bir adımdır. Hızı, doğruluğu ve kullanım kolaylığı sayesinde, hem araştırmacılar hem de geliştiriciler için güçlü bir araç olmaya devam edecektir. Gelecekteki YOLO versiyonlarının, bu trendleri benimseyerek ve yeni inovasyonlarla zenginleşerek bilgisayar görüşünün sınırlarını daha da zorlayacağından eminiz. Aşağıdaki görsel, gelecekteki YZ trendlerini özetlemektedir.
ÖNEMLİ NOKTA
Nesne algılamanın geleceği, daha büyük temel modeller, multimodal veri entegrasyonu, daha verimli edge çözümleri ve etik yapay zeka prensipleri üzerine inşa edilecektir. YOLO, bu evrimin önemli bir parçası olmaya devam edecektir.
Sıkça Sorulan Sorular (SSS)
Q. YOLO v8’in önceki versiyonlardan başlıca farkları nelerdir?
YOLO v8, özellikle “anchor-free” algılama başlığı, ayrık (decoupled) sınıflandırma ve lokalizasyon başlıkları ile öne çıkar. Ayrıca, daha optimize edilmiş bir omurga ve gelişmiş veri artırma teknikleri sayesinde önceki versiyonlara göre hem daha hızlı hem de daha doğru performans sunar.
Q. Kendi özel veri setimle YOLO v8 modelini eğitmek için ne kadar veriye ihtiyacım var?
Genel bir kural olarak, iyi bir başlangıç için her sınıf başına en az 100-200 etiketli örneğe sahip olmanız önerilir. Ancak, daha sağlam ve genellenebilir bir model için binlerce görüntü ve her sınıf için 500’den fazla örnek ideal olacaktır. Transfer öğrenimi kullanarak daha az veriyle de iyi sonuçlar elde edilebilir.
Q. Gerçek zamanlı nesne algılama için hangi donanımı önerirsiniz?
Yüksek FPS değerleri elde etmek için kesinlikle bir NVIDIA GPU önerilir. NVIDIA RTX 30 serisi (örneğin, RTX 3070, 3080) veya daha yeni RTX 40 serisi kartlar, ev kullanıcıları ve küçük ölçekli projeler için mükemmel performans sunar. Profesyonel ve büyük ölçekli uygulamalar için NVIDIA A100 veya H100 gibi veri merkezi GPU’ları tercih edilebilir.
Q. Eğitilmiş YOLO v8 modelimi mobil cihazlarda kullanabilir miyim?
Evet, YOLO v8 modelleri mobil cihazlarda dağıtılmak üzere optimize edilebilir. Modelinizi TFLite (Android için) veya Core ML (iOS için) gibi hafif formatlara dönüştürerek mobil uygulamalarınıza entegre edebilirsiniz. Bu süreçte genellikle YOLO v8’in daha küçük versiyonları (nano veya small) tercih edilir.
YOLO ile Gerçek Zamanlı Algılama Yolculuğunuz Başlasın!
Bu kapsamlı rehberle, YOLO v8 kullanarak kendi gerçek zamanlı nesne algılama modellerinizi geliştirme ve dağıtma konusunda sağlam bir temel oluşturduğunuzu umuyoruz. 2026’nın teknolojileriyle donatılmış bu güçlü algoritma, bilgisayar görüşü projelerinizde size yeni ufuklar açacaktır.
Sorularınız mı var? Deneyimlerinizi ve projelerinizi bizimle paylaşmak ister misiniz? Yorum bırakın ve Kwontrol topluluğuna katılın!