

ÖZET
Bulutta Felaket Kurtarma Stratejileri 2026
Bulut ortamlarında iş sürekliliğini ve yüksek erişilebilirliği sağlamak için felaket kurtarma stratejilerini keşfedin.
Anahtar Kelimeler: Felaket Kurtarma, Bulut Bilişim, İş Sürekliliği
İÇİNDEKİLER
1 Arka Plan ve Giriş: Neden Felaket Kurtarma?
2 Felaket Kurtarma Temelleri ve Hedefleri: RTO ve RPO
3 Bulut Sağlayıcılarına Göre Felaket Kurtarma Çözümleri
4 Problem Çözme: Yaygın Zorluklar ve Pratik Yaklaşımlar
5 Pratik Uygulama: Etkili Bir Felaket Kurtarma Planı Oluşturma
6 Kapanış: Gelecek Öngörüleri ve En İyi Uygulamalar
GİRİŞ
Arka Plan ve Giriş: Neden Felaket Kurtarma?
Günümüzün dijital ekonomisinde, işletmelerin faaliyetlerini kesintisiz sürdürebilmesi hayati önem taşımaktadır. Bu bağlamda, Felaket Kurtarma (Disaster Recovery) stratejileri, özellikle bulut bilişim ortamlarında, iş sürekliliği ve yüksek erişilebilirlik sağlamak için vazgeçilmez bir unsur haline gelmiştir. 2026 yılı itibarıyla, siber saldırılar, doğal afetler, donanım arızaları veya insan hataları gibi beklenmedik olaylar, her ölçekten işletme için ciddi tehditler oluşturmaya devam etmektedir. Bu tür felaketler, veri kaybına, hizmet kesintilerine ve dolayısıyla büyük finansal kayıplara ve itibar zedelenmesine yol açabilir.
“Bulut tabanlı sistemlerin esnekliği ve ölçeklenebilirliği, felaket kurtarma çözümlerini daha erişilebilir ve maliyet etkin hale getiriyor; ancak doğru stratejiyi seçmek kritik.”
— Kwontrol Analiz Ekibi, 2026
Geleneksel on-premise altyapılarda felaket kurtarma kurulumu, genellikle yüksek maliyetli yedek veri merkezleri, karmaşık donanım ve yazılım yatırımları gerektirirken, bulut bilişim bu süreci demokratikleştirmiştir. Amazon Web Services (AWS), Microsoft Azure ve Google Cloud Platform (GCP) gibi önde gelen bulut sağlayıcıları, işletmelerin felaket kurtarma yeteneklerini çok daha uygun maliyetlerle ve daha hızlı bir şekilde devreye almalarına olanak tanıyan gelişmiş hizmetler sunmaktadır. Bu yazıda, bulutta felaket kurtarma stratejilerinin temel prensiplerini, RTO (Recovery Time Objective) ve RPO (Recovery Point Objective) gibi kritik metrikleri, farklı bulut sağlayıcılarının sunduğu çözümleri ve etkili bir DR planı oluşturmak için pratik adımları detaylı bir şekilde inceleyeceğiz. Amacımız, işletmelerin 2026 ve sonrasında dijital varlıklarını güvence altına almalarına yardımcı olmaktır.
ÖNEMLİ NOKTA
Bulutta felaket kurtarma, geleneksel yöntemlere göre daha esnek, ölçeklenebilir ve maliyet etkin çözümler sunar. Ancak her işletmenin ihtiyaçları farklı olduğundan, doğru stratejinin belirlenmesi ve düzenli testler yapılması esastır.
ANALİZ
Felaket Kurtarma Temelleri ve Hedefleri: RTO ve RPO
Felaket kurtarma planlamasının temelini, işletmenin ne kadar süre kesintiye dayanabileceği ve ne kadar veri kaybını göze alabileceği soruları oluşturur. Bu soruların cevapları, Kurtarma Süresi Hedefi (RTO – Recovery Time Objective) ve Kurtarma Noktası Hedefi (RPO – Recovery Point Objective) olarak bilinen iki kritik metrikle belirlenir. Bu hedefler, seçilecek felaket kurtarma stratejisinin maliyetini ve karmaşıklığını doğrudan etkiler.
RTO ve RPO: İş Sürekliliğinin İki Temel Taşı
RTO (Recovery Time Objective) — Bir felaket durumunda sistemlerin ne kadar süre içinde yeniden çalışır duruma getirileceğini belirleyen maksimum kabul edilebilir kesinti süresi. Örneğin, 4 saatlik bir RTO, sistemlerin en geç 4 saat içinde kurtarılması gerektiği anlamına gelir.
RPO (Recovery Point Objective) — Bir felaket durumunda kaybedilebilecek maksimum veri miktarıdır. Son yedekten bu yana geçen süreyi ifade eder. Örneğin, 1 saatlik bir RPO, en kötü senaryoda son 1 saatlik verinin kaybedilebileceği anlamına gelir.
RTO ve RPO hedeflerini belirlerken, işletmenin kritik iş süreçleri, yasal ve düzenleyici gereklilikler, müşteri beklentileri ve finansal etkiler göz önünde bulundurulmalıdır. Daha düşük RTO ve RPO hedefleri (örneğin, saniyeler veya dakikalar), genellikle daha karmaşık ve maliyetli DR çözümleri gerektirir.
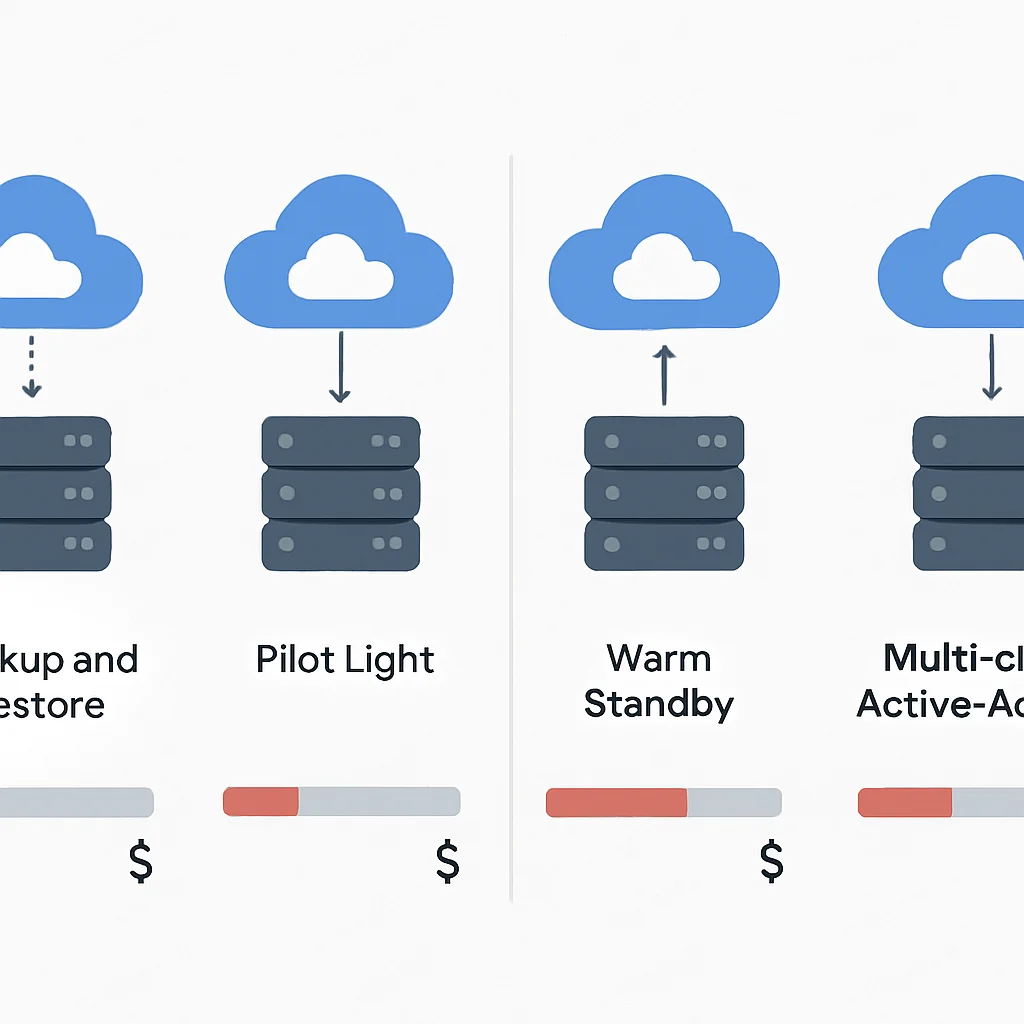
Bulutta Felaket Kurtarma Stratejileri
Bulut ortamlarında uygulanabilecek başlıca felaket kurtarma stratejileri şunlardır:
Felaket Kurtarma Stratejilerinin Karşılaştırması
| Strateji | Açıklama | RTO | RPO | Maliyet |
|---|---|---|---|---|
| Yedekleme ve Geri Yükleme | Veriler düzenli olarak yedeklenir ve bir felaket durumunda kurtarma bölgesine geri yüklenir. | Saatler | Saatler | Düşük |
| Pilot Işık (Pilot Light) | Minimum düzeyde bir altyapı (veritabanları) her zaman çalışır durumda tutulur, felaket anında diğer kaynaklar devreye alınır. | Dakikalar/Saatler | Dakikalar | Orta |
| Sıcak Bekleme (Warm Standby) | Kurtarma bölgesinde tam işlevsel ancak daha küçük ölçekli bir altyapı sürekli çalışır. Felaket anında ölçek büyütülür. | Dakikalar | Dakikalar/Saniyeler | Orta/Yüksek |
| Çoklu Bölge/Aktif-Aktif (Multi-Site Active-Active) | Uygulama, birden fazla bölgede eş zamanlı olarak tam ölçekte çalışır. Yük, bölgeler arasında dağıtılır. | Saniyeler | Saniyeler/Sıfır | Yüksek |
ÖNEMLİ NOKTA
Felaket kurtarma stratejisi seçimi, belirlenen RTO/RPO hedefleriyle doğrudan ilişkilidir. Daha düşük RTO/RPO, genellikle daha yüksek maliyet ve daha karmaşık bir altyapı anlamına gelir. İşletmeler, bu dengeyi kendi risk toleranslarına ve bütçelerine göre kurmalıdır.
ÇÖZÜMLER
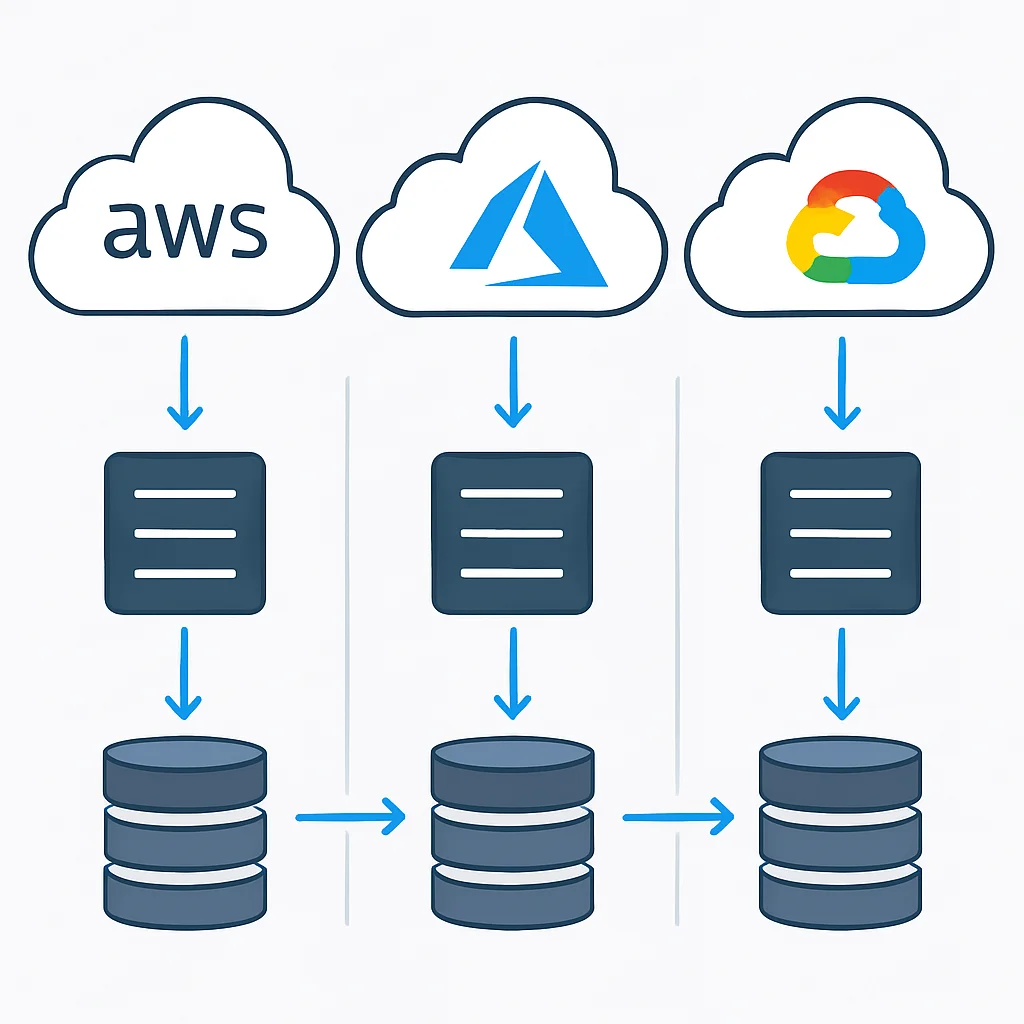
Bulut Sağlayıcılarına Göre Felaket Kurtarma Çözümleri
Önde gelen bulut sağlayıcıları, işletmelerin farklı RTO/RPO hedeflerine ulaşmalarını sağlayacak geniş bir felaket kurtarma hizmetleri yelpazesi sunar. Her bir platformun kendine özgü güçlü yönleri ve entegrasyonları bulunmaktadır.
Amazon Web Services (AWS) Felaket Kurtarma
AWS, küresel altyapısı ve geniş hizmet portföyü ile felaket kurtarma için kapsamlı çözümler sunar.
- AWS Backup: Verilerinizi merkezi olarak yedeklemek ve yönetmek için kullanılır. EC2 instance’ları, EBS birimleri, RDS veritabanları gibi birçok AWS hizmetini destekler.
- Amazon S3: Yüksek dayanıklılık ve erişilebilirliğe sahip nesne depolama hizmeti. Yedeklemeler ve arşivlemeler için idealdir. Çapraz bölge replikasyonu (CRR) ile veriler farklı coğrafi bölgelere otomatik olarak kopyalanabilir.
- AWS CloudFormation: Altyapıyı kod olarak (IaC) tanımlayarak, DR ortamlarının hızlı ve tutarlı bir şekilde oluşturulmasını sağlar. Pilot Işık veya Sıcak Bekleme senaryolarında kurtarma bölgesindeki kaynakların otomatik olarak devreye alınmasında kritik rol oynar.
- AWS Elastic Disaster Recovery (DRS): Fiziksel sunuculardan, VMware, Azure ve GCP gibi diğer bulut ortamlarından AWS’ye felaket kurtarma sağlayan bir hizmettir. Sürekli veri replikasyonu ile RPO’yu saniyelere düşürebilir.
- Amazon Route 53: DNS hizmeti olarak, felaket anında trafiği kurtarma bölgesine yönlendirmek için kullanılır.
KOD AÇIKLAMASI
Bu AWS CloudFormation şablonu, basit bir “Pilot Işık” felaket kurtarma senaryosunda kullanılacak bir EC2 instance’ı ve bir RDS veritabanını kurtarma bölgesinde tanımlar. Bu kaynaklar, asıl ortam çöktüğünde hızlıca ölçeklendirilebilir.
AWSTemplateFormatVersion: '2010-09-09'
Description: Basit bir Pilot Işık Felaket Kurtarma altyapısı için CloudFormation şablonu.
Resources:
RecoveryVPC:
Type: AWS::EC2::VPC
Properties:
CidrBlock: 10.0.0.0/16
EnableDnsSupport: 'true'
EnableDnsHostnames: 'true'
Tags:
- Key: Name
Value: RecoveryVPC
RecoverySubnet:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref RecoveryVPC
CidrBlock: 10.0.1.0/24
AvailabilityZone: !Select [0, !GetAZs ''] # Kurtarma bölgesi AZ'si
Tags:
- Key: Name
Value: RecoverySubnet
RecoveryDBInstance:
Type: AWS::RDS::DBInstance
Properties:
DBInstanceIdentifier: kwontrol-recovery-db
DBInstanceClass: db.t3.micro # Pilot ışık için küçük instance
Engine: postgres
MasterUsername: admin
MasterUserPassword: yourpassword # Gerçek ortamda Secrets Manager kullanın
AllocatedStorage: '20'
DBSnapshotIdentifier: your-latest-snapshot # Son yedekleme snapshot'ı
PubliclyAccessible: 'false'
VPCSecurityGroups:
- !Ref RecoveryDBSecurityGroup
DBSubnetGroupName: !Ref RecoveryDBSubnetGroup
RecoveryDBSubnetGroup:
Type: AWS::RDS::DBSubnetGroup
Properties:
DBSubnetGroupDescription: Recovery DB Subnet Group
SubnetIds:
- !Ref RecoverySubnet
RecoveryDBSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Enable access to RDS
VpcId: !Ref RecoveryVPC
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: '5432'
ToPort: '5432'
CidrIp: 0.0.0.0/0 # Sadece test amaçlı, üretimde kısıtlayın
Microsoft Azure Felaket Kurtarma
Azure, geniş kurumsal müşteri tabanı için entegre ve yönetilebilir DR çözümleri sunar.
- Azure Site Recovery (ASR): Şirket içi sanal makineler (VMware, Hyper-V) ve Azure VM’leri için sürekli replikasyon ve otomatik kurtarma sağlar. RTO ve RPO hedeflerini dakikalara düşürebilir.
- Azure Backup: Azure VM’leri, SQL Server, SAP HANA veritabanları ve dosya paylaşımları için bulut tabanlı yedekleme çözümü. Uzun süreli saklama ve geri yükleme yetenekleri sunar.
- Azure Traffic Manager: DNS tabanlı bir yük dengeleyici olarak, uygulamaların farklı bölgelerdeki dağıtılmış uç noktaları arasında trafiği yönlendirerek yüksek erişilebilirlik ve yanıt hızı sağlar. Felaket anında trafiği kurtarma bölgesine yönlendirebilir.
- Azure SQL Database Active Geo-Replication: SQL veritabanları için okunabilir ikincil kopyalar oluşturarak felaket kurtarma ve yüksek erişilebilirlik sağlar.
KOD AÇIKLAMASI
Bu Azure CLI komutu, bir Azure VM’i için Site Recovery’i etkinleştirir. Bu, VM’in verilerinin belirtilen kurtarma bölgesine sürekli olarak replike edilmesini sağlar, böylece bir felaket durumunda hızlı bir şekilde kurtarılabilir.
az site-recovery replication-protected-item create \
--resource-group "source-rg" \
--account-name "recovery-vault-name" \
--policy-name "replication-policy-name" \
--vm-name "source-vm-name" \
--primary-nic "source-vm-nic" \
--secondary-region "eastus2" \
--name "my-protected-item" \
--replication-provider "Azure" \
--resource-id "/subscriptions/<subscription-id>/resourceGroups/source-rg/providers/Microsoft.Compute/virtualMachines/source-vm-name"
Google Cloud Platform (GCP) Felaket Kurtarma
GCP, yüksek performanslı ağı ve küresel altyapısı ile felaket kurtarma için modern ve ölçeklenebilir çözümler sunar.
- Cloud Storage: Veri yedeklemeleri ve arşivlemeleri için çok bölgeli depolama seçenekleri sunar. Otomatik nesne yaşam döngüsü yönetimi ve sürüm oluşturma ile veri kaybı riski minimize edilir.
- Compute Engine: Otomatik ölçeklendirme grupları ve bölgeler arası yük dengeleme ile yüksek erişilebilir VM’ler oluşturulabilir. Felaket anında kurtarma bölgesinde VM’lerin hızlıca başlatılması sağlanır.
- Cloud DNS: DNS tabanlı trafik yönetimi ile felaket anında trafiği ikincil bir bölgeye yönlendirebilir.
- Cloud SQL ve Cloud Spanner: Yönetilen veritabanı hizmetleri, bölgeler arası replikasyon ve otomatik yedeklemeler ile yüksek dayanıklılık ve kurtarılabilirlik sağlar. Özellikle Cloud Spanner, global olarak dağıtılmış, güçlü tutarlılığa sahip veritabanı yetenekleri sunar.
- Anthos: Hibrit ve çoklu bulut ortamlarında tutarlı bir yönetim katmanı sağlayarak felaket kurtarma stratejilerini basitleştirir.
ÖNEMLİ NOKTA
Her bulut sağlayıcısının DR çözümleri, kendi ekosistemlerine özgü avantajlar sunar. İşletmelerin mevcut altyapıları, bütçeleri ve teknik yetkinlikleri doğrultusunda en uygun platformu seçmeleri ve bu platformun DR hizmetlerini derinlemesine anlamaları gerekmektedir.
ZORLUKLAR VE ÇÖZÜMLER
Problem Çözme: Yaygın Zorluklar ve Pratik Yaklaşımlar
Bulutta felaket kurtarma, birçok avantaj sunsa da, planlama ve uygulama aşamasında belirli zorluklarla karşılaşmak mümkündür. Bu bölümde, yaygın sorunları ve bunlara yönelik pratik çözüm yaklaşımlarını inceleyeceğiz.
SORUN 01
Veri Senkronizasyonu ve Tutarlılığı
Özellikle düşük RPO hedefleri olan sistemlerde, ana ve kurtarma bölgeleri arasındaki verilerin sürekli ve tutarlı bir şekilde senkronize edilmesi büyük bir zorluktur. Veri tutarsızlıkları, kurtarma sonrası operasyonlarda ciddi sorunlara yol açabilir.
ÇÖZÜM — Gelişmiş Replikasyon ve Veritabanı Mimarileri
Çözüm: Bulut sağlayıcılarının sunduğu yönetilen veritabanı hizmetlerinin (AWS RDS Multi-AZ, Azure SQL Active Geo-Replication, GCP Cloud SQL Cross-Region Replication) veya özel veritabanı replikasyon araçlarının (örneğin, PostgreSQL için WAL-E veya pgBackRest) kullanılması. Uygulama düzeyinde de veri tutarlılığını sağlamak için tasarımlar yapılmalı (örneğin, idempotent işlemler).
# AWS RDS Multi-AZ (Örnek)
aws rds create-db-instance \
--db-instance-identifier my-prod-db \
--db-instance-class db.t3.medium \
--engine postgres \
--master-username admin \
--master-user-password yourpassword \
--allocated-storage 100 \
--multi-az \
--backup-retention-period 7 \
--region us-east-1
# Bu komut, veritabanını otomatik olarak farklı bir Availability Zone'da replike eder.
# Felaket anında otomatik failover sağlar.
SORUN 02
Maliyet Optimizasyonu
Düşük RTO/RPO hedefleri genellikle daha fazla kaynak (sürekli çalışan sunucular, sürekli replikasyon) gerektirir ve bu da maliyetleri artırır. İşletmeler, DR yatırımı ile potansiyel kesinti maliyetleri arasında doğru dengeyi bulmakta zorlanabilir.
ÇÖZÜM — Kademeli DR Stratejileri ve Otomasyon
Çözüm: Tüm uygulamalar için aynı DR stratejisini uygulamak yerine, iş kritikliklerine göre kademeli bir yaklaşım benimsemek. Örneğin, kritik uygulamalar için “Sıcak Bekleme” veya “Aktif-Aktif” kullanırken, daha az kritik uygulamalar için “Pilot Işık” veya “Yedekleme ve Geri Yükleme” tercih edilebilir. Ayrıca, bulutun esnekliğinden faydalanarak, kurtarma bölgesindeki kaynakları sadece ihtiyaç duyulduğunda (felaket anında veya test sırasında) otomatik olarak devreye alan otomasyonlar (CloudFormation, Terraform, Azure ARM şablonları) kurmak maliyetleri düşürür.
# AWS Lambda ile otomatik kapatma/açma (maliyet optimizasyonu için)
# Bu basit bir örnek olup, gerçek senaryoda daha kompleks bir mantık gerekebilir.
import boto3
def lambda_handler(event, context):
ec2 = boto3.client('ec2')
# Tüm EC2 instance'larını durdur (DR ortamında kullanılmayanlar için)
# Gerçek senaryoda tag bazlı filtreleme yapılmalıdır.
response = ec2.describe_instances(Filters=[
{
'Name': 'instance-state-name',
'Values': ['running']
},
{
'Name': 'tag:Environment', # Örnek: 'DR-NonCritical' tag'ine sahip olanlar
'Values': ['DR-NonCritical']
}
])
instance_ids = []
for reservation in response['Reservations']:
for instance in reservation['Instances']:
instance_ids.append(instance['InstanceId'])
if instance_ids:
ec2.stop_instances(InstanceIds=instance_ids)
print(f"Durdurulan instance'lar: {instance_ids}")
else:
print("Durdurulacak instance bulunamadı.")
return {
'statusCode': 200,
'body': 'İşlem tamamlandı.'
}
“Felaket kurtarma planları, yalnızca teknolojik çözümlerden ibaret değildir; aynı zamanda süreçlerin, iletişimin ve insan faktörünün de entegre edildiği kapsamlı bir yaklaşımdır.”
— Kwontrol Güvenlik Uzmanı, 2026
UYGULAMA
Pratik Uygulama: Etkili Bir Felaket Kurtarma Planı Oluşturma
Etkili bir felaket kurtarma planı, sadece teknolojik bileşenlerden ibaret değildir; aynı zamanda kapsamlı bir analiz, doğru strateji seçimi, düzenli testler ve sürekli iyileştirme süreçlerini de içerir. İşte adım adım bir felaket kurtarma planı oluşturma rehberi:
1
İş Etki Analizi (BIA) ve Risk Değerlendirmesi
İlk adım, hangi uygulamaların ve verilerin iş için kritik olduğunu belirlemektir. Her bir iş sürecinin kesintiye uğramasının potansiyel finansal ve operasyonel etkilerini değerlendirin. Bu analizler sonucunda her uygulama için uygun RTO ve RPO hedefleri belirlenmelidir. Ayrıca, olası felaket senaryolarını (siber saldırı, doğal afet, donanım arızası vb.) ve bunların sistemler üzerindeki potansiyel etkilerini değerlendirerek bir risk matrisi oluşturun.
2
Felaket Kurtarma Stratejisi ve Mimarisinin Seçimi
Belirlenen RTO ve RPO hedeflerine ve bütçe kısıtlamalarına göre en uygun DR stratejisini (Yedekleme ve Geri Yükleme, Pilot Işık, Sıcak Bekleme, Aktif-Aktif) seçin. Seçilen stratejiye uygun bulut hizmetlerini (AWS DRS, Azure Site Recovery, GCP Cloud Storage vb.) ve mimariyi tasarlayın. Bu aşamada, ağ topolojisi, veri replikasyon mekanizmaları, güvenlik önlemleri ve kurtarma adımları detaylandırılmalıdır.
3
Uygulama, Otomasyon ve Dokümantasyon
Seçilen DR stratejisini bulut ortamında uygulayın. Bu süreçte Infrastructure as Code (IaC) araçlarını (CloudFormation, Terraform) kullanarak altyapının otomatik olarak oluşturulmasını sağlayın. Kurtarma adımlarını otomatikleştirmek için betikler (scriptler) ve otomasyon araçları kullanın. Tüm DR planını, kurtarma prosedürlerini, iletişim planını ve sorumlulukları detaylı bir şekilde belgeleyin. Bu dokümantasyon, felaket anında hızlı ve hatasız hareket etmek için kritik öneme sahiptir.
4
Düzenli Test ve İyileştirme
Bir DR planının etkinliği, ancak düzenli testlerle doğrulanabilir. Felaket kurtarma tatbikatları (failover testleri), planın işe yaradığını, RTO/RPO hedeflerine ulaşılabildiğini ve ekibin kurtarma süreçlerine hakim olduğunu gösterir. Testler sırasında ortaya çıkan eksiklikler veya iyileştirme alanları belirlenmeli ve plan güncellenmelidir. Bu süreç, sürekli bir döngü halinde devam etmelidir, çünkü altyapı ve uygulama gereksinimleri zamanla değişebilir.
ÖNEMLİ NOKTA
DR planı, canlı bir doküman olmalı ve teknolojik gelişmeler, iş gereksinimleri veya altyapı değişiklikleriyle birlikte düzenli olarak gözden geçirilmeli ve güncellenmelidir. Yalnızca kâğıt üzerinde kalan bir plan, gerçek bir felaket anında işe yaramayacaktır.
SONUÇ
Kapanış: Gelecek Öngörüleri ve En İyi Uygulamalar
2026 ve sonrasında, bulutta felaket kurtarma stratejileri, yapay zeka (AI) ve makine öğrenimi (ML) gibi teknolojilerin entegrasyonuyla daha da gelişecektir. AI/ML, anormallik tespiti, potansiyel kesintilerin tahmini ve kurtarma süreçlerinin otomatikleştirilmesi gibi alanlarda önemli rol oynayabilir. Örneğin, sistem günlüklerini ve metriklerini analiz ederek felaket belirtilerini önceden tespit edebilir ve otomatik kurtarma adımlarını tetikleyebilir.
AI/ML’in Felaket Kurtarmadaki Artıları
✓ Proaktif Tehdit Tespiti: Anormal davranışları hızlıca belirleyerek potansiyel felaketleri önceden haber verir.
✓ Otomatik Kurtarma Kararları: Belirli senaryolarda insan müdahalesi olmadan otomatik failover ve kurtarma eylemlerini tetikler.
✓ Optimizasyon: Kaynak kullanımını ve maliyetleri optimize etmek için DR altyapısını dinamik olarak ayarlar.
✓ Daha Hızlı RTO/RPO: Kurtarma süreçlerini hızlandırarak RTO ve RPO hedeflerine daha kolay ulaşmayı sağlar.
AI/ML’in Felaket Kurtarmadaki Eksileri
✗ Karmaşıklık: AI/ML modellerinin entegrasyonu ve yönetimi ek karmaşıklık getirebilir.
✗ Başlangıç Maliyeti: Gelişmiş AI/ML tabanlı çözümlerin başlangıç maliyetleri yüksek olabilir.
✗ Güven ve Şeffaflık: Otomatik kararların güvenilirliği ve şeffaflığı konusunda endişeler olabilir.
En iyi uygulamalar açısından, işletmelerin şu noktalara dikkat etmesi önemlidir:
- Otomasyonu Benimseyin: Kurtarma süreçlerini mümkün olduğunca otomatikleştirmek, insan hatasını azaltır ve RTO’yu iyileştirir.
- Düzenli Test Edin: DR planları sadece birer belge olarak kalmamalı, düzenli olarak canlı ortamda veya simüle edilmiş ortamlarda test edilmelidir.
- Maliyetleri İzleyin: Bulutun esnekliği, DR maliyetlerini optimize etme fırsatı sunar. Kullanılmayan kaynakları kapatmak veya daha uygun fiyatlı depolama seçeneklerini kullanmak gibi stratejiler geliştirin.
- Güvenliğe Odaklanın: DR ortamının da ana ortam kadar güvenli olduğundan emin olun. Veri şifreleme, erişim kontrolleri ve güvenlik denetimleri ihmal edilmemelidir.
- Eğitim ve Farkındalık: DR planından sorumlu tüm ekibin planı anlaması ve rollerini bilmesi sağlanmalıdır.
UYARI
En iyi felaket kurtarma planı bile, düzenli olarak test edilmezse başarısız olabilir. Testler, planın güncel kalmasını ve beklenmedik sorunların önceden tespit edilmesini sağlar. Gerçek bir felaket anında test edilmemiş bir plan, operasyonel kaosa yol açabilir.

Sıkça Sorulan Sorular (SSS)
Q. RTO ve RPO arasındaki temel fark nedir?
RTO (Recovery Time Objective), bir felaket sonrası sistemlerin ne kadar sürede yeniden çalışır hale geleceğini, yani maksimum kabul edilebilir kesinti süresini ifade eder. RPO (Recovery Point Objective) ise, bir felaket durumunda kaybedilebilecek maksimum veri miktarını, yani son yedekten bu yana geçen süreyi belirtir.
Q. Bulutta felaket kurtarma neden geleneksel yöntemlerden daha avantajlıdır?
Bulutta felaket kurtarma, geleneksel yöntemlere göre daha düşük maliyetlidir çünkü fiziksel donanım yatırımı gerektirmez. Ayrıca, daha yüksek esneklik, ölçeklenebilirlik ve bölgeler arası dağıtım imkanı sunarak daha düşük RTO/RPO hedeflerine ulaşmayı kolaylaştırır. Otomasyon ve yönetilen hizmetler sayesinde kurulum ve yönetim de basitleşir.
Q. Bir felaket kurtarma planı ne sıklıkla test edilmelidir?
Felaket kurtarma planları, en az yılda bir kez veya sistemde önemli bir değişiklik (yeni uygulama, altyapı değişikliği vb.) olduğunda test edilmelidir. Düzenli ve gerçekçi testler, planın güncel ve işlevsel kalmasını sağlar, ekibin hazırlıklı olmasını ve potansiyel sorunların önceden tespit edilmesini mümkün kılar.
Q. Farklı bulut sağlayıcıları arasında felaket kurtarma stratejileri nasıl karşılaştırılır?
AWS, Azure ve GCP gibi bulut sağlayıcıları, benzer DR stratejilerini (yedekleme, pilot ışık, sıcak bekleme) desteklese de, kullandıkları hizmet isimleri ve entegrasyon yöntemleri farklılık gösterir. Örneğin, AWS’de DRS, Azure’da Site Recovery, GCP’de ise Cloud Storage ve Compute Engine kombinasyonları ön plana çıkar. Seçim yaparken mevcut altyapınız, bütçeniz ve ekibinizin yetkinlikleri göz önünde bulundurulmalıdır.
Okuduğunuz için teşekkürler!
Dijital varlıklarınızı güvence altına almak, 2026’da her zamankinden daha kritik. Umarım bu rehber, bulutta felaket kurtarma stratejilerinizi geliştirmenize yardımcı olmuştur.
Sorularınız mı var? Yorum bırakın veya Kwontrol ekibimizle iletişime geçin!