

ÖZET
Uygulama İzleme ve Log Yönetimi: Prometheus, Grafana ve ELK Stack ile Tam Gözlemlenebilirlik 2026
Uygulamalarınızın performansını ve sağlığını Prometheus, Grafana ve ELK Stack ile nasıl izleyeceğinizi öğrenin.
Anahtar Kelimeler: Prometheus, Grafana, ELK Stack
İÇİNDEKİLER
1. Arka Plan ve Giriş: Gözlemlenebilirliğin Önemi
2. Prometheus: Metrik Toplamanın Kalbi
3. Grafana: Veri Görselleştirmenin Gücü
4. ELK Stack: Kapsamlı Log Yönetimi ve Analizi
5. Tam Gözlemlenebilirlik: Metrikler, Loglar ve İzleme Entegrasyonu
6. Pratik Uygulama: Basit Bir İzleme Yığını Kurulumu
7. Problem Çözme: Yaygın Zorluklar ve Çözümleri
8. Sıkça Sorulan Sorular
GİRİŞ
Arka Plan ve Giriş: Gözlemlenebilirliğin Önemi
Günümüzün hızla değişen dijital dünyasında, işletmelerin ve son kullanıcıların beklentileri her zamankinden daha yüksek. Uygulamaların kesintisiz çalışması, yüksek performans sunması ve herhangi bir sorun anında hızla tespit edilip çözülmesi kritik önem taşıyor. 2026 yılına gelindiğinde, mikro hizmet mimarileri, sunucusuz işlevler ve bulut tabanlı dağıtık sistemler norm haline gelmiş durumda. Bu karmaşık yapıları yönetmek, geleneksel izleme yöntemleriyle neredeyse imkansız hale geliyor.
İşte bu noktada “gözlemlenebilirlik” (observability) kavramı devreye giriyor. Gözlemlenebilirlik, bir sistemin iç durumunu, sistemin dışarıya yaydığı verileri (metrikler, loglar, izler) analiz ederek ne kadar iyi anlayabileceğinizi ifade eder. Bu, sadece bir hata meydana geldiğinde uyarı almakla kalmayıp, hatanın nedenini hızlıca bulmanızı ve hatta potansiyel sorunları önceden tahmin etmenizi sağlar. Gözlemlenebilirlik, modern DevOps pratiğinin temel taşlarından biridir ve sistem sağlığını, performansını ve güvenliğini sağlamak için vazgeçilmezdir.
Bu yazıda, uygulama izleme ve log yönetiminin kalbinde yer alan üç güçlü aracı inceleyeceğiz: Prometheus metrik toplama için, Grafana bu metrikleri görselleştirmek ve uyarılar oluşturmak için, ve ELK Stack (Elasticsearch, Logstash, Kibana) ise kapsamlı log yönetimi ve analizi için. Bu araçların 2026’daki rolünü, nasıl entegre edildiklerini ve tam gözlemlenebilirlik sağlamak için nasıl kullanılabileceğini detaylıca ele alacağız.
ÖNEMLİ NOKTA
2026 itibarıyla, dağıtık sistemlerin karmaşıklığı, geleneksel izleme yaklaşımlarını yetersiz kılmaktadır. Gözlemlenebilirlik, proaktif sorun tespiti ve hızlı çözüm için metrikler, loglar ve izlerin entegre bir şekilde analiz edilmesini gerektirir.
METRİK İZLEME
Prometheus: Metrik Toplamanın Kalbi
Prometheus, Cloud Native Computing Foundation (CNCF) tarafından inkübe edilen ve günümüzde en popüler açık kaynaklı sistem izleme ve uyarı araçlarından biridir. Özellikle dinamik bulut ortamları ve mikro hizmet mimarileri için tasarlanmıştır. Geleneksel izleme sistemlerinin aksine, Prometheus “çekme (pull)” modelini benimser; yani izlenecek hedeflerden (uygulamalar, sunucular, veritabanları vb.) metrikleri kendisi çeker.
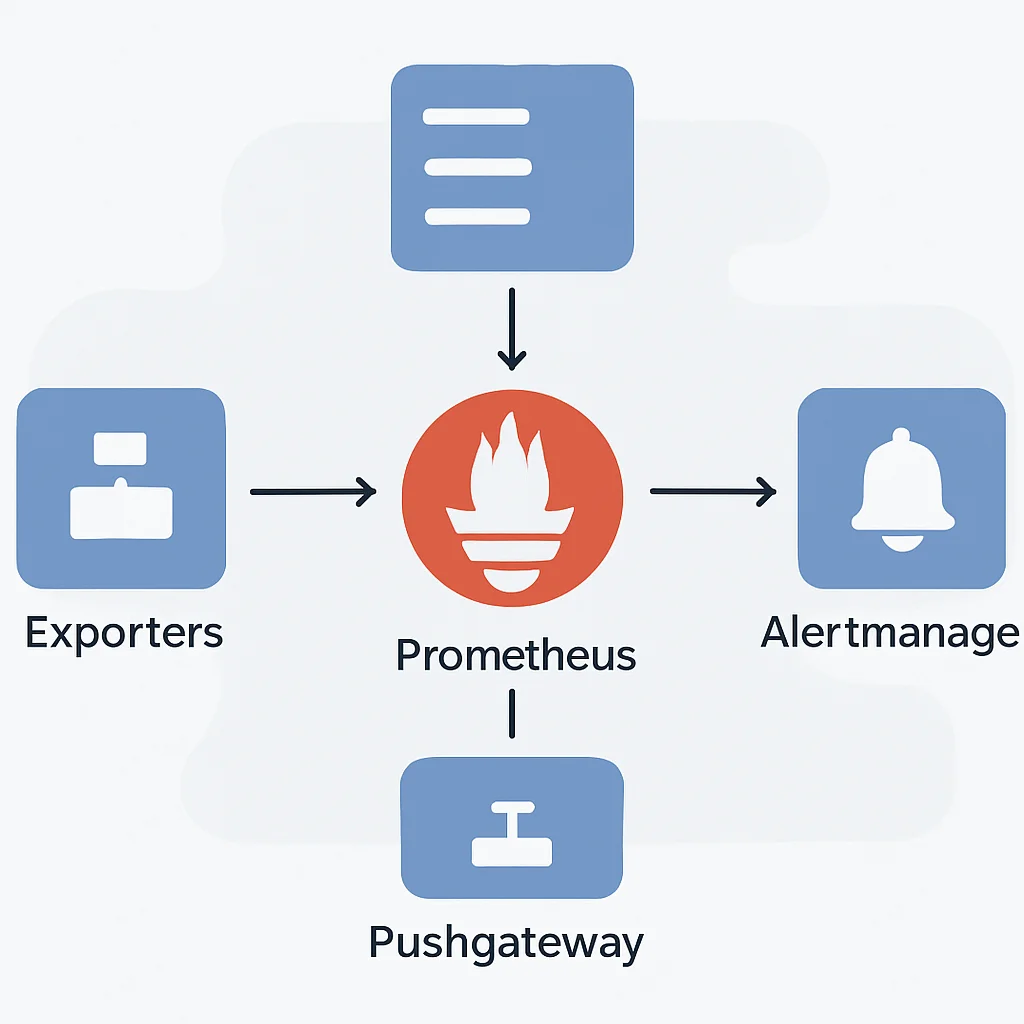
Prometheus Mimarisi ve Çalışma Prensibi
Prometheus’un temel bileşenleri şunlardır:
1. Prometheus Sunucusu: Metrikleri toplar, depolar ve sorgular. Zaman serisi veritabanı (TSDB) ile entegredir.
2. Exporter’lar: Hedef sistemlerden metrikleri Prometheus’un anlayacağı formatta (HTTP endpoint üzerinden) sunan aracılardır. Örneğin, Node Exporter sunucu işletim sistemi metriklerini, cAdvisor ise container metriklerini sağlar.
3. Pushgateway: Kısa ömürlü işlerden (batch jobs) metrik toplamak için kullanılır. Prometheus’un pull modeline istisna teşkil eder.
4. Alertmanager: Prometheus sunucusu tarafından üretilen alarmları işler, gruplandırır, susturur ve bildirim kanallarına (e-posta, Slack, PagerDuty vb.) yönlendirir.
5. Service Discovery: Dinamik ortamlar için hedef sistemleri otomatik olarak keşfeder (Kubernetes, AWS EC2, Consul vb. ile entegrasyon).
Prometheus, metrikleri etiketlerle (labels) zenginleştirerek güçlü sorgulama yetenekleri sunar. Örneğin, bir HTTP isteğinin durum kodunu (status_code="200") veya bir uygulamanın çalıştığı ortamı (environment="production") etiket olarak ekleyebilirsiniz. Bu etiketler, karmaşık filtreleme ve gruplandırma işlemleri yapmanıza olanak tanır.
PromQL: Prometheus Sorgu Dili
PromQL, Prometheus’un kendi sorgu dilidir. Zaman serisi verileri üzerinde güçlü ve esnek sorgular yazmanızı sağlar. Ortalama, toplam, oran gibi matematiksel işlemleri kolayca yapabilir, belirli bir zaman aralığındaki metrik davranışını analiz edebilirsiniz. PromQL, sisteminiz hakkında derinlemesine bilgi edinmek için vazgeçilmezdir.
KOD AÇIKLAMASI
Aşağıdaki PromQL sorgusu, “my_application_http_requests_total” metriğinin son 5 dakikadaki HTTP durum kodlarına göre artış oranını hesaplar. Bu, uygulamamızın başarılı (2xx), istemci hatası (4xx) veya sunucu hatası (5xx) yanıtlarının dakikadaki ortalama sayısını görmemizi sağlar.
sum by (status_code) (rate(my_application_http_requests_total{job="my_app"}[5m]))Bu sorgu, my_app işinden gelen HTTP isteklerinin toplam sayısını status_code etiketine göre gruplandırarak, son 5 dakikadaki değişim oranını gösterir. Böylece, hangi durum kodlarının daha sık döndüğünü ve sistemdeki anormallikleri hızla tespit edebiliriz. Örneğin, 5xx hata kodlarının oranında ani bir artış, ciddi bir sunucu sorununa işaret edebilir.
ÖNEMLİ NOKTA
Prometheus’un etiket tabanlı veri modeli ve güçlü PromQL sorgu dili, özellikle dinamik ve dağıtık sistemlerde detaylı performans analizi ve sorun tespiti için benzersiz bir esneklik sunar.
GÖRSELLEŞTİRME
Grafana: Veri Görselleştirmenin Gücü
Grafana, metrikleri görselleştirmek ve izlemek için kullanılan açık kaynaklı bir platformdur. Prometheus, Elasticsearch, Graphite, InfluxDB gibi birçok farklı veri kaynağını destekler. Grafana’nın en büyük avantajı, kullanıcı dostu arayüzü sayesinde karmaşık metrik verilerini anlamlı ve etkileşimli panolara dönüştürme yeteneğidir. Bu panolar, sistem sağlığını bir bakışta anlamanızı, trendleri izlemenizi ve anormallikleri hızla tespit etmenizi sağlar.
Grafana ile Panolar Oluşturma
Grafana panoları, farklı türde panellerden oluşur. Her panel, belirli bir veri kaynağındaki bir veya daha fazla metriği görselleştirir. Yaygın panel türleri şunlardır:
1. Grafikler (Graph): Zaman serisi verilerini çizgi grafikleriyle gösterir. En yaygın panel türüdür.
2. Tek Değer (Singlestat): Belirli bir metriğin anlık değerini büyük bir sayı veya gösterge olarak gösterir.
3. Tablo (Table): Metrik verilerini tablo formatında sunar.
4. Isı Haritası (Heatmap): Zaman içindeki veri dağılımını yoğunlukla gösterir, özellikle gecikme süreleri gibi veriler için kullanışlıdır.
Bir Grafana panosu oluşturmak için, öncelikle bir veri kaynağı (örneğin Prometheus) yapılandırmanız gerekir. Ardından, yeni bir pano ekleyip panelleri istediğiniz metriklerle doldurabilirsiniz. PromQL sorgularını doğrudan Grafana panellerinde kullanarak, Prometheus’tan aldığınız verileri görselleştirebilirsiniz.
Uyarı ve Bildirimler
Grafana, sadece görselleştirme aracı değildir; aynı zamanda güçlü bir uyarı sistemine sahiptir. Belirli metrik eşik değerleri aşıldığında veya belirli bir desen gözlemlendiğinde (örneğin, CPU kullanımı %90’ın üzerine çıktığında), Grafana uyarılar tetikleyebilir ve bu uyarıları e-posta, Slack, Microsoft Teams, PagerDuty gibi çeşitli kanallara gönderebilir. Prometheus’un Alertmanager’ı ile entegre çalışarak, uyarıların daha gelişmiş bir şekilde yönetilmesini sağlar.
ÖNEMLİ NOKTA
Grafana, Prometheus’tan gelen ham metrik verilerini anlamlı, etkileşimli ve özelleştirilebilir panolar aracılığıyla görselleştirerek, sistem sağlığı hakkında hızlı ve kapsamlı bir genel bakış sunar. Uyarı mekanizmaları ise proaktif sorun yönetimi için kritik öneme sahiptir.
LOG YÖNETİMİ
ELK Stack: Kapsamlı Log Yönetimi ve Analizi
Uygulama izlemenin metrikler ayağını Prometheus ve Grafana ile ele alırken, gözlemlenebilirliğin diğer kritik ayağı olan log yönetimi için ELK Stack (Elasticsearch, Logstash, Kibana) devreye girer. ELK Stack, dağıtık sistemlerden gelen büyük hacimli log verilerini merkezi bir konumda toplamak, işlemek, depolamak, aramak ve görselleştirmek için güçlü bir çözümdür.
ELK Stack Bileşenleri
1. Elasticsearch: Dağıtık, RESTful bir arama ve analiz motorudur. Tüm log verilerini indeksler ve hızlı sorgulama imkanı sunar. Büyük veri kümelerinde saniyeler içinde arama yapabilir.
2. Logstash: Veri işleme boru hattıdır. Farklı kaynaklardan (dosyalar, ağ, veritabanları vb.) logları alır, ayrıştırır, zenginleştirir (örneğin IP adreslerinden coğrafi konum bilgisi ekler) ve Elasticsearch’e gönderir.
3. Kibana: Elasticsearch’teki verileri keşfetmek, analiz etmek ve görselleştirmek için kullanılan bir web arayüzüdür. Log verilerini grafikler, tablolar ve diğer görselleştirmelerle anlamlı hale getirir.
Bu üç bileşen, logların yaşam döngüsünü baştan sona yönetir: toplama, işleme, depolama, arama ve görselleştirme. Genellikle, logları kaynak sistemlerden Logstash’e göndermek için Beats ailesinden ajanlar (örneğin Filebeat veya Metricbeat) kullanılır. Filebeat, dosyalardan logları okur ve Logstash veya doğrudan Elasticsearch’e iletir; hafif ve kaynak dostu bir çözümdür.
Logstash ile Veri İşleme
Logstash, gelen logları yapılandırılmış verilere dönüştürmede kritik bir rol oynar. filter eklentileri sayesinde, ham log satırlarını ayrıştırabilir, belirli alanları çıkarabilir, veri tiplerini dönüştürebilir ve hatta koşullu işlemler uygulayabiliriz. Bu işlem, Kibana’da daha anlamlı sorgular ve görselleştirmeler oluşturmak için log verilerini standardize eder.
KOD AÇIKLAMASI
Aşağıdaki Logstash yapılandırması, bir Apache erişim günlüğünü ayrıştırmak için grok filtresini kullanır. Bu, ham log satırındaki bilgileri (IP adresi, istek yöntemi, URL, durum kodu vb.) ayrı alanlara bölerek Elasticsearch’te kolayca sorgulanabilir hale getirir.
input {
beats {
port => 5044
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
target => "@timestamp"
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "apache-logs-%{+YYYY.MM.dd}"
}
}Bu örnekte, Logstash Filebeat’ten (5044 portu) gelen logları alır, COMBINEDAPACHELOG deseniyle ayrıştırır, zaman damgasını standardize eder ve clientip alanından coğrafi konum bilgisi ekler. Son olarak, işlenmiş logları günlük bazda indekslenen Elasticsearch’e gönderir.
Kibana ile Log Analizi
Kibana, Elasticsearch’teki verileriniz için bir pencere görevi görür. Discover modülü ile ham logları arayabilir, filtreleyebilir ve inceleyebilirsiniz. Visualize modülü ile log verilerinden grafikler, pie chart’lar, bar grafikleri oluşturabilir ve bunları Dashboard‘larda bir araya getirebilirsiniz. Bu, hata ayıklama, güvenlik analizi, performans sorunlarını giderme ve kullanıcı davranışlarını anlama gibi birçok senaryoda loglarınızı etkin bir şekilde kullanmanızı sağlar.
ÖNEMLİ NOKTA
ELK Stack, merkezi log yönetimi ve analizi için güçlü bir çözüm sunar. Logstash’ın veri işleme yetenekleri ve Elasticsearch’in hızlı arama performansı, Kibana’nın esnek görselleştirme yetenekleriyle birleşerek, sistem sorunlarını loglar üzerinden derinlemesine inceleme imkanı tanır.
ENTEGRASYON
Tam Gözlemlenebilirlik: Metrikler, Loglar ve İzleme Entegrasyonu
Prometheus/Grafana ve ELK Stack, her biri gözlemlenebilirliğin farklı bir temel direğini (metrikler ve loglar) temsil eder. Ancak gerçek anlamda tam gözlemlenebilirlik, bu araçların entegre bir şekilde çalışmasıyla elde edilir. Üçüncü temel direk olan “izler” (traces) ise dağıtık sistemlerde bir isteğin farklı servisler arasındaki yolculuğunu takip etmeyi sağlar ve genellikle Jaeger veya Zipkin gibi araçlarla yönetilir. Bu yazının kapsamı gereği loglar ve metrikler üzerine odaklanacağız.
Neden Entegrasyon Önemli?
Bir sistemde bir sorunla karşılaşıldığında, metrikler genellikle sorunun varlığını ve genel etkisini gösterir. Örneğin, bir uygulamanın HTTP hata oranının %5’ten %50’ye çıktığını bir Grafana panosunda görebilirsiniz. Ancak bu metrik, hatanın tam olarak neden kaynaklandığını söylemez. İşte bu noktada loglar devreye girer. Loglar, hatanın kök nedenini, hangi kullanıcının etkilendiğini, hangi parametrelerle çağrıldığını ve ne zaman meydana geldiğini gösteren detaylı bilgiler sunar.
Entegre bir yaklaşım, bu iki veri türü arasında sorunsuz geçiş yapmanızı sağlar. Grafana panolarınızdan doğrudan ilgili loglara atlayarak, metriklerde gördüğünüz bir anormalliğin altındaki detayı hızla inceleyebilirsiniz. Bu, problem çözme süresini (MTTR – Mean Time To Resolution) önemli ölçüde kısaltır ve operasyonel verimliliği artırır.
Prometheus/Grafana ve ELK Entegrasyon Stratejileri
Bu iki yığını entegre etmenin birkaç yolu vardır:
1. Grafana’dan Kibana’ya Derin Bağlantı: Grafana panellerinize, belirli bir zaman aralığı ve filtrelerle Kibana’ya yönlendiren doğrudan bağlantılar ekleyebilirsiniz. Böylece, bir metrikte anormallik gördüğünüzde, tek tıklamayla ilgili logları Kibana’da inceleyebilirsiniz.
2. Elasticsearch Metrikleri: Bazı durumlarda, Elasticsearch’ten metrikleri doğrudan Grafana’da görselleştirmek isteyebilirsiniz. Grafana’nın Elasticsearch veri kaynağı eklentisi sayesinde bu mümkündür, ancak Prometheus kadar esnek veya performanslı olmayabilir.
3. Ortak Etiketleme/Kimliklendirme: Uygulamalarınızın hem metriklerinde hem de loglarında tutarlı etiketler (örneğin, service_name, pod_id) kullanmak, iki sistem arasında korelasyon kurmayı kolaylaştırır.
Karşılaştırmalı Analiz: Prometheus ve ELK Stack
Prometheus — Yüksek performanslı zaman serisi metrik toplama ve sorgulama için optimize edilmiştir. Anlık sistem durumu ve trend analizi için idealdir.
ELK Stack — Yapılandırılmamış ve yarı yapılandırılmış log verilerinin merkezi toplanması, işlenmesi, depolanması ve aranması için tasarlanmıştır. Detaylı hata ayıklama ve güvenlik analizi için vazgeçilmezdir.
Entegrasyon — En iyi sonuçlar için her iki yığının da birlikte kullanılması önerilir. Metrikler sorunun nerede olduğunu gösterirken, loglar sorunun nedenini açıklar.
ÖNEMLİ NOKTA
Tam gözlemlenebilirlik, metrikler ve logların entegre bir şekilde kullanılmasıyla elde edilir. Prometheus ve Grafana, sistemin “ne” olduğunu gösterirken, ELK Stack loglar aracılığıyla “neden” olduğunu açıklar. Bu entegrasyon, hızlı sorun tespiti ve çözümü için hayati önem taşır.
UYGULAMA
Pratik Uygulama: Basit Bir İzleme Yığını Kurulumu
Şimdi, Prometheus, Grafana ve ELK Stack’i kullanarak basit bir izleme ve log yönetimi yığını kurmak için adımları inceleyelim. Bu, genellikle Docker veya Kubernetes gibi konteyner orkestrasyon araçları kullanılarak yapılır, ancak temel prensipler aynı kalır. Bir Linux sunucusunda temel bir kurulum senaryosunu ele alalım.
1
Prometheus ve Node Exporter Kurulumu
Bir sunucuya Prometheus ve Node Exporter’ı kurarak sistem metriklerini toplamaya başlayın. Node Exporter, CPU, bellek, disk G/Ç ve ağ gibi işletim sistemi metriklerini sunar. Prometheus’un yapılandırma dosyasında (prometheus.yml) Node Exporter’ı bir hedef olarak tanımlayın.
KOD AÇIKLAMASI
Aşağıdaki Prometheus yapılandırma örneği, Node Exporter’ı localhost:9100 adresinde bir hedef olarak tanımlar.
scrape_configs:
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100']2
Grafana Kurulumu ve Yapılandırması
Grafana’yı kurun ve Prometheus’u bir veri kaynağı olarak ekleyin. Ardından, Node Exporter metriklerini görselleştiren hazır panoları içe aktarabilir veya kendi panolarınızı oluşturabilirsiniz. Örneğin, Grafana Labs’ın sağladığı “Node Exporter Full” panosu (ID: 1860) harika bir başlangıç noktasıdır.
3
ELK Stack Kurulumu
Elasticsearch, Logstash ve Kibana’yı kurun. Docker Compose veya Kubernetes operatörleri ile kurulum, manuel kurulumdan daha kolaydır. Elasticsearch’in doğru bir şekilde kümelendiğinden ve Logstash ile Kibana’nın Elasticsearch’e erişebildiğinden emin olun.
4
Filebeat ile Log Toplama
Loglarını toplamak istediğiniz her sunucuya Filebeat’i kurun. Filebeat yapılandırmasında (filebeat.yml), hangi log dosyalarını izleyeceğini ve logları Logstash’e veya doğrudan Elasticsearch’e göndereceğini belirtin. Örneğin, Nginx erişim loglarını toplamak için Nginx modülünü etkinleştirebilirsiniz.
KOD AÇIKLAMASI
Aşağıdaki Filebeat yapılandırması, Nginx erişim ve hata loglarını Logstash’e gönderir.
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
- /var/log/nginx/error.log
output.logstash:
hosts: ["localhost:5044"]Kullanım Örneği: Performans Düşüşü Tespiti
Bir e-ticaret uygulamasında CPU kullanımının aniden %80’in üzerine çıktığını fark ettiniz. Grafana panosunda bu artışı gördükten sonra, ilgili sunucunun loglarını Kibana’da inceleyerek hangi uygulamanın veya isteğin bu artışa neden olduğunu hızlıca tespit edebilirsiniz. Örneğin, belirli bir ürün sayfasına gelen yoğun isteklerin sunucu kaynaklarını tükettiğini loglardan görebilirsiniz.
ÖNEMLİ NOKTA
Yukarıdaki adımlar, temel bir izleme ve log yönetimi yığını kurmak için bir başlangıç noktasıdır. Üretim ortamlarında, bu araçların ölçeklenebilirliği, güvenliği ve yedekliliği için daha fazla yapılandırma ve otomasyon gereklidir (örneğin, Kubernetes için Helm grafikleri veya Terraform ile otomasyon).
PROBLEM ÇÖZME
Problem Çözme: Yaygın Zorluklar ve Çözümleri
Prometheus, Grafana ve ELK Stack gibi güçlü araçlar kullanmak, gözlemlenebilirlik yolculuğunuzda önemli avantajlar sağlasa da, beraberinde bazı zorlukları da getirebilir. Bu zorlukların farkında olmak ve proaktif çözümler geliştirmek, izleme altyapınızın verimliliğini ve sürdürülebilirliğini artıracaktır.
SORUN 01
Yüksek Veri Hacmi ve Depolama Maliyeti
Özellikle loglar ve yüksek çözünürlüklü metrikler, kısa sürede terabaytlarca veri oluşturabilir. Bu durum, depolama maliyetlerini artırır ve sorgu performansını düşürebilir. 2026’da bile, bulut depolama maliyetleri büyük ölçekli uygulamalar için önemli bir kalemdir.
ÇÖZÜM — Veri Saklama Politikaları ve Ölçeklendirme
1. Veri Saklama Politikaları: Eski logları ve metrikleri daha düşük maliyetli depolama alanlarına taşımak veya belirli bir süre sonra silmek için politikalar belirleyin. Örneğin, 30 günlük logları sıcak depolamada tutarken, daha eski logları arşivleyebilir veya silebilirsiniz.
2. Downsampling (Örnekleme): Uzun vadeli metrikler için daha düşük çözünürlüklü veri tutun. Örneğin, 1 dakikalık çözünürlükteki metrikleri 30 gün sonra 5 dakikalık ortalamalara düşürebilirsiniz.
3. Ölçeklenebilir Mimari: Elasticsearch için yatay ölçeklendirme (sharding ve replikasyon) ve Prometheus için uzun vadeli depolama entegrasyonları (Thanos, Cortex) kullanın.
SORUN 02
Alarm Yorgunluğu (Alert Fatigue)
Çok fazla uyarı, gerçek sorunları gözden kaçırmanıza neden olabilir. Gereksiz veya düşük öncelikli uyarılar, ekiplerin dikkatini dağıtır ve operasyonel verimliliği düşürür.
ÇÖZÜM — Akıllı Uyarı Yapılandırması
1. Uyarı Eşiklerini Ayarlayın: Eşikleri, sadece gerçek sorunları tetikleyecek şekilde dikkatlice belirleyin. Deneme yanılma yoluyla optimum eşikleri bulun.
2. Uyarı Gruplama: Alertmanager’ın gruplama ve susturma (silencing) özelliklerini kullanarak ilgili uyarıları birleştirin ve gürültüyü azaltın.
3. Önceliklendirme: Uyarılara öncelik seviyeleri atayın ve farklı önceliklerdeki uyarıları farklı kanallara veya farklı ekiplere gönderin.
4. Anomaly Detection: AI/ML tabanlı anomali tespiti araçlarını kullanarak, belirlenmiş eşikler yerine normal davranıştan sapmaları tespit edin. Bu, 2026’da giderek daha yaygın hale gelmektedir.
SORUN 03
Görselleştirme ve Analiz Karmaşıklığı
Çok sayıda metrik ve log alanı, anlamlı panolar ve sorgular oluşturmayı zorlaştırabilir. Özellikle yeni başlayanlar için Kibana ve Grafana’nın tüm özelliklerini kullanmak karmaşık gelebilir.
ÇÖZÜM — Standartlaştırma ve Eğitim
1. Standart Panolar ve Şablonlar: Ekip genelinde kullanılacak standart panolar ve şablonlar oluşturun. Grafana’nın “Dashboard as Code” yaklaşımı (örneğin JSON şablonları), bu süreci otomatikleştirebilir.
2. Veri Standardizasyonu: Logstash filtreleri ve Prometheus etiketleri aracılığıyla log ve metrik verilerini tutarlı bir şekilde yapılandırın. Bu, sorgulamayı ve görselleştirmeyi büyük ölçüde basitleştirir.
3. Eğitim ve Dokümantasyon: Ekiplerin bu araçları etkin bir şekilde kullanabilmesi için düzenli eğitimler ve kapsamlı dokümantasyon sağlayın. En iyi uygulamaları paylaşın.
ÖNEMLİ NOKTA
Gözlemlenebilirlik araçlarının kurulumu sadece başlangıçtır. Veri hacmi yönetimi, akıllı uyarı mekanizmaları ve kullanıcı dostu görselleştirmeler, uzun vadeli başarı için kritik öneme sahiptir.
Sıkça Sorulan Sorular
Q. Prometheus ve ELK Stack arasındaki temel fark nedir?
Prometheus, sistem metriklerini (CPU kullanımı, bellek tüketimi, istek sayısı vb.) zaman serisi olarak toplamak ve analiz etmek için tasarlanmıştır. ELK Stack ise uygulamalardan ve altyapıdan gelen yapılandırılmamış/yarı yapılandırılmış log verilerini merkezi olarak toplamak, işlemek, depolamak ve aramak için kullanılır.
Q. Tam gözlemlenebilirlik için neden hem metrikler hem de loglar gereklidir?
Metrikler, bir sistemin genel durumu ve performans eğilimleri hakkında nicel bilgi verirken (örneğin, “CPU kullanımı yüksek”). Loglar ise belirli olayların detaylı kaydını tutarak sorunun kök nedenini anlamaya yardımcı olur (örneğin, “hangi kullanıcı isteğinin CPU kullanımını artırdığı”). Birlikte, sorunun hem “ne” olduğunu hem de “neden” olduğunu anlamamızı sağlarlar.
Q. Grafana, Prometheus’suz veya ELK’siz kullanılabilir mi?
Evet, Grafana çok çeşitli veri kaynaklarını destekleyen bağımsız bir görselleştirme aracıdır. Prometheus veya ELK Stack olmadan da Graphite, InfluxDB, PostgreSQL, MySQL gibi diğer veri kaynaklarından veri çekerek panolar oluşturabilir ve uyarılar yapılandırabilirsiniz.
Q. Logstash yerine doğrudan Elasticsearch’e log göndermek mümkün müdür?
Evet, Filebeat ve diğer Beats ajanları doğrudan Elasticsearch’e log gönderebilir. Logstash genellikle logları ayrıştırma, zenginleştirme veya dönüştürme gibi daha karmaşık işleme adımları gerektiğinde kullanılır. Basit log toplama senaryolarında Logstash’i atlamak, altyapıyı basitleştirebilir.
Q. 2026’da gözlemlenebilirlik trendleri nelerdir?
2026’da gözlemlenebilirlik, yapay zeka ve makine öğrenimi destekli AIOps çözümlerine doğru evrilmektedir. Anomali tespiti, kök neden analizi otomasyonu ve tahmine dayalı izleme, bu alandaki önemli trendler arasında yer almaktadır. Ayrıca OpenTelemetry gibi standartlar, izleme verilerinin farklı araçlar arasında taşınmasını kolaylaştırmaktadır.
SONUÇ
Kapanış: Geleceğin Gözlemlenebilirliği
2026 yılında, dinamik ve dağıtık sistemlerin yönetimi, güçlü gözlemlenebilirlik araçları olmadan düşünülemez. Bu yazıda ele aldığımız Prometheus, Grafana ve ELK Stack, modern uygulama izleme ve log yönetimi için sektörde kanıtlanmış ve yaygın olarak kullanılan çözümlerdir. Metriklerin toplanması, görselleştirilmesi, uyarıların yönetilmesi ve logların kapsamlı analizi, sistemlerinizin sağlığını ve performansını güvence altına almanın temelini oluşturur.
Bu araçların entegre bir şekilde kullanılması, bir sorunun sadece varlığını değil, aynı zamanda kök nedenini de hızla tespit etmenizi sağlar. Metriklerdeki bir anormallik, sizi ilgili loglara yönlendirir ve böylece problem çözme süreniz önemli ölçüde kısalır. Bu proaktif yaklaşım, hem operasyonel maliyetleri azaltır hem de son kullanıcı deneyimini iyileştirir.
Gelecekte, gözlemlenebilirlik alanındaki gelişmeler yapay zeka ve makine öğrenimi entegrasyonlarıyla daha da hızlanacaktır. AIOps çözümleri, anomali tespiti, kök neden analizi ve tahmine dayalı izleme gibi yetenekleri otomatikleştirerek, insan müdahalesini en aza indirecek ve operasyonel ekiplerin daha stratejik görevlere odaklanmasını sağlayacaktır. Kwontrol olarak, bu trendleri yakından takip etmeye ve en güncel bilgilerle sizlere rehberlik etmeye devam edeceğiz.
Uygulamalarınızın ve altyapınızın tam gözlemlenebilirliğini sağlamak, sadece bir lüks değil, 2026’nın rekabetçi ortamında bir zorunluluktur. Bu araçları etkin bir şekilde kullanarak, sistemlerinizin her zaman optimum performansta çalıştığından emin olabilirsiniz.
Okuduğunuz için teşekkürler!
Uygulama izleme ve log yönetimi yolculuğunuzda başarılar dileriz. Unutmayın, iyi bir gözlemlenebilirlik, daha istikrarlı ve güvenilir sistemler anlamına gelir.
Sorularınız mı var? Yorum bırakın veya Kwontrol.com adresini ziyaret edin!