
ÖZET
[Backend] NoSQL Veritabanları Karşılaştırması: MongoDB, Cassandra, Redis ve Neo4j 2026
Modern uygulama geliştirme için doğru NoSQL veritabanını seçmek kritik. Bu kapsamlı rehberde MongoDB, Cassandra, Redis ve Neo4j’nin özelliklerini, kullanım alanlarını ve performanslarını detaylıca karşılaştırıyoruz.
Keywords: NoSQL, Veritabanı Seçimi, Backend 2026
ARKA PLAN
NoSQL Veritabanları: Neden ve Nasıl 2026?
2026 yılına geldiğimizde, modern uygulama geliştirmenin hızı ve karmaşıklığı, geleneksel ilişkisel veritabanlarının (SQL) sınırlarını zorlamaya devam ediyor. Büyük veri, gerçek zamanlı analizler, mikro hizmet mimarileri ve yüksek ölçeklenebilirlik ihtiyacı, geliştiricileri NoSQL veritabanlarına yönlendiriyor. NoSQL, “Not only SQL” (Sadece SQL değil) anlamına gelir ve farklı veri modelleri sunarak belirli iş yükleri için daha optimize çözümler sağlar.
Geleneksel SQL veritabanları, ACID (Atomicity, Consistency, Isolation, Durability) garantileriyle finans ve işlem tabanlı sistemlerde hala vazgeçilmezdir. Ancak, örneğin, sosyal medya akışları, IoT cihaz verileri veya oyun skor tabloları gibi senaryolarda esneklik, yatay ölçeklenebilirlik ve yüksek performans daha öncelikli hale gelmiştir. Bu noktada NoSQL veritabanları devreye girer. Yüksek hacimli ve hızlı değişen verileri yönetme yetenekleri sayesinde, günümüzün dinamik dijital ekosisteminde kritik bir rol oynamaktadırlar.
Bugün, bir backend geliştiricisi olarak, doğru veritabanı seçimi projenizin başarısını doğrudan etkileyebilir. Yanlış bir seçim, performans darboğazlarına, yüksek maliyetlere ve gelecekteki ölçeklenebilirlik sorunlarına yol açabilir. Bu yüzden, piyasadaki önde gelen NoSQL çözümlerini anlamak ve projelerinizin özel ihtiyaçlarına göre en uygun olanı seçmek hayati önem taşımaktadır. Bu yazıda, dört popüler NoSQL veritabanı olan MongoDB, Cassandra, Redis ve Neo4j’yi derinlemesine inceleyecek, güçlü ve zayıf yönlerini karşılaştıracağız.
ÖNEMLİ NOKTA
2026’da NoSQL veritabanı seçimi, sadece teknik bir karar olmaktan öte, uygulamanızın gelecekteki büyümesini, performansını ve maliyet etkinliğini belirleyen stratejik bir karardır. Projenizin veri modeli, ölçeklenebilirlik ihtiyacı ve sorgu desenleri bu kararda belirleyici rol oynar.
Yukarıdaki diyagramda görüldüğü gibi, veri mimarileri zamanla evrilmiştir. Tek bir ilişkisel veritabanının tüm ihtiyaçları karşıladığı monolitik yapılardan, her biri belirli bir iş yükü için optimize edilmiş birden fazla veritabanının kullanıldığı poliglottik persistance mimarilerine geçiş, modern backend sistemlerinin temelini oluşturmaktadır. Bu yaklaşım, her bir servisin veya modülün kendi veri depolama çözümünü seçmesine olanak tanır, böylece genel sistem performansı ve esnekliği artar.
ANALİZ
NoSQL Veritabanı Türleri ve Doğru Seçim Kriterleri
NoSQL veritabanları, veri depolama modellerine göre dört ana kategoriye ayrılır. Her bir kategori, belirli veri türleri ve erişim desenleri için optimize edilmiştir:
1. Belge Tabanlı (Document-Oriented) Veritabanları
Bu veritabanları, verileri JSON, BSON veya XML gibi yarı yapılandırılmış belgeler olarak depolar. Her belge bağımsızdır ve kendi yapısına sahiptir, bu da şema esnekliği sağlar. Uygulama geliştiricileri için oldukça sezgiseldir çünkü veriler doğrudan uygulama kodundaki nesnelerle eşleşir. MongoDB bu kategorinin en bilinen örneğidir.
Kullanım Alanları: İçerik yönetim sistemleri, e-ticaret katalogları, blog platformları, mobil uygulamalar.
2. Anahtar-Değer (Key-Value) Veritabanları
En basit NoSQL modelidir. Her veri öğesi, benzersiz bir anahtar ve ilişkili bir değerden oluşur. Değer herhangi bir veri türünde olabilir (metin, sayı, resim, hatta karmaşık bir nesne). Anahtar-değer çiftleri çok hızlı okuma/yazma işlemleri sunar. Redis ve Amazon DynamoDB bu kategoride yer alır.
Kullanım Alanları: Önbellekleme (caching), oturum yönetimi, gerçek zamanlı skor tabloları, basit veri depolama.
3. Sütun Ailesi (Column-Family) Veritabanları
Verileri satırlar ve dinamik sütunlardan oluşan “sütun aileleri” şeklinde depolar. Yüksek yazma performansı ve yatay ölçeklenebilirlik için tasarlanmıştır. Genellikle büyük ölçekli, dağıtık sistemlerde ve yüksek hacimli veri akışlarında tercih edilir. Apache Cassandra ve HBase bu modelin önde gelen temsilcileridir.
Kullanım Alanları: Zaman serisi verileri, IoT sensör verileri, mesajlaşma sistemleri, büyük veri analitiği.
4. Grafik (Graph) Veritabanları
Verileri düğümler (nodes), kenarlar (edges) ve özellikler (properties) kullanarak depolar. İlişkiler, verinin kendisi kadar önemlidir ve sorgu performansında merkezi bir rol oynar. Karmaşık ilişkileri olan veriler için idealdir. Neo4j bu alandaki en popüler veritabanıdır.
Kullanım Alanları: Sosyal ağlar, dolandırıcılık tespiti, tavsiye motorları, ağ ve IT altyapı yönetimi.
ÖNEMLİ NOKTA
Veritabanı türü seçimi, projenizin temel veri erişim desenleri, veri yapısı ve gelecekteki ölçeklenebilirlik beklentileriyle doğrudan ilişkilidir. Her türün kendine özgü güçlü yanları ve ödünleşimleri vardır.
Doğru NoSQL Veritabanı Seçim Kriterleri
Veri Modeli Uygunluğu — Verilerinizin doğal yapısı hangi NoSQL modeline daha iyi uyuyor? (Belge, Anahtar-Değer, Sütun Ailesi, Grafik)
Ölçeklenebilirlik İhtiyacı — Uygulamanızın ne kadar yatay ölçeklenmesi gerekiyor? Okuma/yazma oranları nasıl?
Performans Hedefleri — Gecikme süresi (latency) ve işlem hacmi (throughput) beklentileriniz neler?
Tutarlılık Seviyesi — Uygulamanız ne kadar güçlü tutarlılığa ihtiyaç duyuyor? (CAP Teoremi: Tutarlılık, Erişilebilirlik, Bölüm Toleransı)
Geliştirici Deneyimi ve Ekosistem — Ekibinizin mevcut yetkinlikleri, topluluk desteği ve entegrasyon kolaylığı.
Maliyet — Donanım, lisanslama (açık kaynak/ticari), operasyonel ve bakım giderleri.
Bu karar ağacı, projenizin temel ihtiyaçlarını belirleyerek doğru NoSQL veritabanı türüne yönelmenize yardımcı olabilir. Örneğin, eğer verileriniz yüksek oranda ilişkili ise ve bu ilişkiler üzerinde karmaşık sorgular yapmanız gerekiyorsa, grafik veritabanları daha uygun bir seçenek olacaktır.
KARŞILAŞTIRMA
Detaylı Karşılaştırma: MongoDB, Cassandra, Redis ve Neo4j
1. MongoDB (Belge Tabanlı)
MongoDB, yüksek performanslı, şemasız, belge tabanlı bir veritabanıdır. Esnek belge modeli sayesinde, verileri JSON benzeri BSON formatında depolar. Bu, geliştiricilerin veri yapılarını hızlı bir şekilde değiştirmesine ve uyarlamasına olanak tanır. MongoDB, özellikle hızlı yineleme gerektiren çevik geliştirme ortamlarında popülerdir.
Özellikler:
- Esnek Şema: Belgeler farklı alanlara sahip olabilir.
- Yüksek Performans: Disk üzerindeki verileri bellekte tutarak hızlı erişim sağlar.
- Yatay Ölçeklenebilirlik: Sharding (parçalama) ile büyük veri kümelerini ve yüksek işlem hacmini yönetir.
- Güçlü Sorgu Dili: Zengin sorgu operatörleri ve Aggregation Framework ile karmaşık analizler yapabilir.
- Replica Setler: Yüksek erişilebilirlik ve veri yedekliliği sağlar.
Kullanım Alanları: E-ticaret siteleri (ürün katalogları), içerik yönetim sistemleri, IoT veri toplama, mobil uygulamaların backend’i.
Performans Notu: MongoDB, özellikle okuma ağırlıklı işlemlerde ve belge bazlı sorgularda oldukça hızlıdır. Tipik bir e-ticaret uygulamasında, ürün detay sayfalarının 10-20ms içinde yüklenmesini sağlayabilir. Yazma işlemleri de genellikle hızlıdır, ancak sharding stratejisi ve index kullanımı performansı kritik derecede etkiler.
KOD AÇIKLAMASI
Aşağıdaki kod örneği, MongoDB’ye Python kullanarak bir belge eklemeyi ve ardından belirli bir kriterle sorgulamayı göstermektedir. PyMongo kütüphanesi kullanılır.
from pymongo import MongoClient
# MongoDB bağlantısı
client = MongoClient('mongodb://localhost:27017/')
db = client.kwontrol_db
users_collection = db.users
# Bir belge ekleme
user_data = {
"name": "Ali Can",
"email": "[email protected]",
"age": 30,
"interests": ["yazılım", "yapay zeka", "veri bilimi"],
"created_at": "2026-04-16T10:00:00Z"
}
result = users_collection.insert_one(user_data)
print(f"Eklenen belgenin ID'si: {result.inserted_id}")
# Belgeyi sorgulama
query = {"age": {"$gt": 25}, "interests": "yapay zeka"}
found_users = users_collection.find(query)
print("\n25 yaşından büyük ve yapay zeka ile ilgilenen kullanıcılar:")
for user in found_users:
print(user)
client.close()
ÖNEMLİ NOKTA
MongoDB’nin şemasız yapısı, hızlı geliştirme ve değişen veri ihtiyaçlarına kolay adaptasyon sağlar. Ancak, büyük ve karmaşık sorgular için indexlerin doğru tasarlanması ve Aggregation Framework’ün etkin kullanımı kritik önem taşır.
2. Apache Cassandra (Sütun Ailesi)
Apache Cassandra, yüksek ölçeklenebilirlik ve yüksek erişilebilirlik için tasarlanmış, dağıtık bir NoSQL veritabanıdır. Facebook tarafından geliştirilen ve daha sonra açık kaynak olarak Apache Vakfı’na bağışlanan Cassandra, petabaytlarca veriyi binlerce sunucuya yayarak, tek bir hata noktası olmaksızın yönetebilir. Özellikle yazma yoğun iş yükleri için optimize edilmiştir.
Özellikler:
- Dağıtık Mimari: Tüm düğümler eşittir (peer-to-peer), bu da yüksek erişilebilirlik ve doğrusal ölçeklenebilirlik sağlar.
- Yüksek Yazma Performansı: Geleneksel veritabanlarına göre çok daha yüksek yazma hızları sunar.
- Hata Toleransı: Veriler birden fazla düğümde çoğaltılır, bu da donanım arızalarına karşı dirençlidir.
- Esnek Veri Modeli: Sütun aileleri ve dinamik sütunlar ile esneklik sağlar.
- CQL (Cassandra Query Language): SQL benzeri bir sorgu dili kullanır, öğrenmesi nispeten kolaydır.
Kullanım Alanları: IoT cihaz verileri, zaman serisi verileri, mesajlaşma sistemleri, dolandırıcılık tespiti, operasyonel zeka.
Performans Notu: Cassandra, 100TB üzeri veri setlerinde ve saniyede milyonlarca yazma işlemi gerektiren durumlarda üstün performans sergiler. Örneğin, bir telekomünikasyon şirketi, günlük 50 milyar sensör verisi kaydını ılımlı gecikme süreleriyle işlemek için Cassandra’yı kullanabilir. Okuma performansı, sorgu desenlerinin ve veri modellemesinin doğru yapılmasına bağlıdır.
KOD AÇIKLAMASI
Aşağıdaki kod örneği, Python için cassandra-driver kullanarak Cassandra’ya bağlanmayı, bir tablo oluşturmayı ve veri eklemeyi göstermektedir.
from cassandra.cluster import Cluster
# Cassandra kümesine bağlanma
cluster = Cluster(['127.0.0.1']) # Localhost'taki Cassandra düğümü
session = cluster.connect()
# Keyspace oluşturma (eğer yoksa)
session.execute("""
CREATE KEYSPACE IF NOT EXISTS kwontrol_keyspace
WITH replication = { 'class': 'SimpleStrategy', 'replication_factor': '1' }
""")
session.set_keyspace('kwontrol_keyspace')
# Tablo oluşturma (eğer yoksa)
session.execute("""
CREATE TABLE IF NOT EXISTS sensor_data (
sensor_id text,
timestamp timestamp,
temperature float,
humidity float,
PRIMARY KEY (sensor_id, timestamp)
) WITH CLUSTERING ORDER BY (timestamp DESC)
""")
# Veri ekleme
session.execute(
"""
INSERT INTO sensor_data (sensor_id, timestamp, temperature, humidity)
VALUES (%s, %s, %s, %s)
""",
("sensor_123", "2026-04-16 10:05:00+0000", 25.5, 60.2)
)
session.execute(
"""
INSERT INTO sensor_data (sensor_id, timestamp, temperature, humidity)
VALUES (%s, %s, %s, %s)
""",
("sensor_123", "2026-04-16 10:06:00+0000", 25.8, 60.5)
)
print("Veriler başarıyla eklendi.")
# Veri sorgulama
rows = session.execute("SELECT * FROM sensor_data WHERE sensor_id = 'sensor_123' LIMIT 2")
print("\nSon 2 sensör verisi:")
for row in rows:
print(row)
cluster.shutdown()
ÖNEMLİ NOKTA
Cassandra’nın gücü, yüksek yazma hacimli ve dağıtık ortamlarda yatar. Veri modellemesi, özellikle birincil anahtar ve kümeleme anahtarlarının doğru tanımlanması, sorgu performansını doğrudan etkiler. Okuma için genellikle önceden tanımlanmış sorgu desenlerine ihtiyaç duyar.
3. Redis (Anahtar-Değer / Bellek İçi)
Redis (Remote Dictionary Server), anahtar-değer depolama modeline sahip, bellek içi (in-memory) bir veri yapısı sunucusudur. Genellikle bir önbellek (cache) veya mesaj aracısı olarak kullanılır, ancak kalıcı veri depolama yetenekleri de mevcuttur. Çeşitli veri yapıları (stringler, hashler, listeler, setler, sıralı setler) sunması, onu çok yönlü kılar.
Özellikler:
- Yüksek Hız: Verileri bellekte tuttuğu için milisaniyenin altında gecikme süreleri sunar.
- Çeşitli Veri Yapıları: String, Hash, List, Set, Sorted Set, Stream gibi zengin veri tipleri.
- Atomik İşlemler: Çoklu komutları tek bir atomik işlem olarak çalıştırabilir.
- Yayın/Abone (Pub/Sub): Gerçek zamanlı mesajlaşma ve bildirim sistemleri için ideal.
- Kalıcılık: RDB (snapshot) ve AOF (append-only file) modları ile verileri diske yazabilir.
Kullanım Alanları: Önbellekleme, oturum yönetimi, gerçek zamanlı skor tabloları, kuyruk sistemleri, sohbet uygulamaları.
Performans Notu: Redis, saniyede yüz binlerce işlem (okuma/yazma) yapabilen ultra hızlı bir çözümdür. Örneğin, bir e-ticaret sitesinde ürün detaylarını önbelleğe alarak, veritabanı yükünü %80 azaltabilir ve kullanıcı yanıt süresini 50ms’den 5ms’ye düşürebilir. Temel kısıtlaması, tüm verinin belleğe sığması gerektiğidir.
KOD AÇIKLAMASI
Aşağıdaki Python kodu, redis-py kütüphanesini kullanarak Redis’e bağlanmayı, bir anahtar-değer çifti ve bir hash veri yapısı üzerinde işlem yapmayı göstermektedir.
import redis
# Redis'e bağlanma
r = redis.Redis(host='localhost', port=6379, db=0)
# String veri tipi: Anahtar-değer ekleme ve okuma
r.set('user:1001:name', 'Ayşe Yılmaz')
print(f"User 1001 Adı: {r.get('user:1001:name').decode('utf-8')}")
# Hash veri tipi: Bir kullanıcının profil bilgilerini depolama
user_profile = {
'email': '[email protected]',
'age': '28',
'city': 'Ankara'
}
r.hmset('user:1001:profile', user_profile)
# Hash'ten veri okuma
profile_data = r.hgetall('user:1001:profile')
print("\nUser 1001 Profil Bilgileri:")
for key, value in profile_data.items():
print(f" {key.decode('utf-8')}: {value.decode('utf-8')}")
# Bir anahtarın süresini belirleme (TTL - Time To Live)
r.setex('temp_data', 60, 'Bu veri 60 saniye sonra silinecek')
print(f"\nTemp data var mı? {r.exists('temp_data')}")
ÖNEMLİ NOKTA
Redis’in en büyük avantajı hızıdır. Bellek içi çalışma prensibi sayesinde düşük gecikme ve yüksek işlem hacmi sunar. Ancak, tüm verilerin bellekte tutulması gerektiği için büyük veri setleri için maliyetli olabilir ve kalıcılık seçenekleri dikkatli yönetilmelidir.
4. Neo4j (Grafik Veritabanı)
Neo4j, ilişkiler üzerine odaklanmış, yerel bir grafik veritabanıdır. Verileri düğümler (entities), kenarlar (relationships) ve özellikler (attributes) olarak depolar. İlişkiler, verinin kendisi kadar önemlidir ve sorgu performansında merkezi bir rol oynar. Karmaşık, bağlantılı veri setleri üzerinde hızlı ve derinlemesine analizler yapmak için tasarlanmıştır.
Özellikler:
- İlişkiler Merkezi: İlişkileri birinci sınıf vatandaş olarak ele alır, bu da karmaşık bağlantıların hızlıca sorgulanmasını sağlar.
- Cypher Sorgu Dili: Sezgisel, görsel bir sorgu dili olan Cypher’ı kullanır.
- ACID Garantisi: Geleneksel SQL veritabanları gibi ACID özelliklerini destekler.
- Yerel Grafik İşleme: Veri depolama ve işleme için grafik yapısını kullanır.
- Ölçeklenebilirlik: Yatay ölçeklenebilirlik ve yüksek erişilebilirlik için kümeleme (clustering) sunar.
Kullanım Alanları: Sosyal ağlar (arkadaşlık önerileri), dolandırıcılık tespiti (ilişki ağları), tavsiye motorları, bilgi grafikleri, ağ ve altyapı yönetimi.
Performans Notu: Neo4j, ilişkisel derinliği olan sorgularda üstün performans gösterir. Örneğin, bir sosyal ağda “X kullanıcısının arkadaşlarının arkadaşlarının hangi filmleri beğendiğini bul” gibi 5-6 derinlikteki bir sorguyu milisaniyeler içinde yanıtlayabilir. İlişkisel veritabanları bu tür sorgular için onlarca JOIN işlemi gerektireceğinden çok daha yavaş olacaktır.
KOD AÇIKLAMASI
Aşağıdaki Cypher sorguları, Neo4j’de düğümler ve ilişkiler oluşturmayı, ardından belirli bir deseni sorgulamayı göstermektedir. Bu, Neo4j Browser veya Python sürücüsü aracılığıyla çalıştırılabilir.
// Düğümler ve ilişkiler oluşturma
CREATE (ali:Person {name: 'Ali'}),
(ayse:Person {name: 'Ayşe'}),
(film1:Movie {title: 'Matrix'}),
(film2:Movie {title: 'Inception'}),
(ali)-[:LIKES]->(film1),
(ayse)-[:LIKES]->(film1),
(ali)-[:FRIENDS_WITH]->(ayse),
(ayse)-[:LIKES]->(film2)
// Sorgu: Ali'nin arkadaşlarının beğendiği filmleri bul
MATCH (ali:Person {name: 'Ali'})-[:FRIENDS_WITH]->(friend:Person)
MATCH (friend)-[:LIKES]->(movie:Movie)
RETURN friend.name AS FriendName, movie.title AS LikedMovie
ÖNEMLİ NOKTA
Neo4j, veriler arasındaki karmaşık ilişkilerin birinci sınıf vatandaş olduğu senaryolarda rakipsizdir. İlişki tabanlı sorgularda performansı olağanüstüdür, ancak basit anahtar-değer veya belge depolama ihtiyaçları için aşırıya kaçan bir çözüm olabilir.
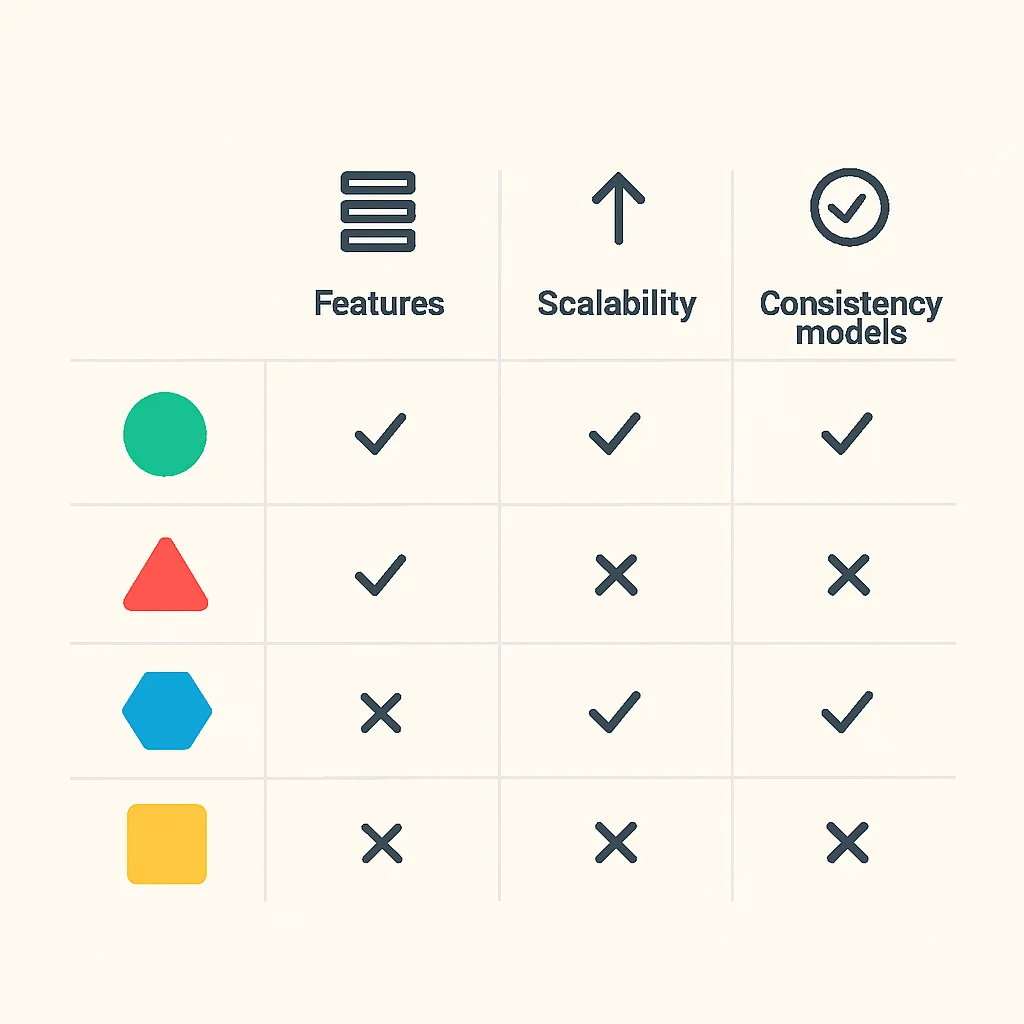
Bu karşılaştırmalı tablo, her bir veritabanının temel özelliklerini, ölçeklenebilirlik modelini ve CAP teoremi bağlamındaki tutarlılık seviyesini özetlemektedir. Seçim yaparken bu temel farkları göz önünde bulundurmak önemlidir.
UYGULAMA
Pratik Uygulama Senaryoları ve En İyi Kullanım Alanları
Her NoSQL veritabanının kendine özgü bir “tatlı noktası” vardır. İşte yaygın pratik senaryolar ve bu senaryolara en uygun veritabanı seçimleri:
Senaryo 1: E-ticaret Ürün Katalogları ve CMS
Ürün bilgileri, müşteri yorumları ve esnek şema gerektiren içerik yönetimi.
En İyi Seçim: MongoDB
Ürünler genellikle karmaşık ve değişken özelliklere sahiptir (boyutlar, renkler, SKU’lar, varyantlar). MongoDB’nin belge tabanlı yapısı, bu esnekliği doğal bir şekilde karşılar. Ayrıca, ürünleri ve ilgili yorumları tek bir belgede depolayarak sorgu performansını artırır. Bir e-ticaret platformunda, ürün detay sayfaları ve arama sonuçları için MongoDB kullanmak, geliştirme hızını ve veri erişimini optimize eder.
Senaryo 2: IoT Cihaz Verileri ve Zaman Serisi Analizi
Yüksek hacimli, sürekli akan sensör verileri ve hızlı yazma/okuma ihtiyacı.
En İyi Seçim: Apache Cassandra
Milyonlarca IoT cihazından gelen terabaytlarca veriyi depolamak ve işlemek Cassandra’nın ana uzmanlık alanıdır. Doğrusal ölçeklenebilirliği ve yüksek yazma performansı, sensör verilerini gerçek zamanlı olarak almayı ve depolamayı kolaylaştırır. Cassandra’nın sütun ailesi modeli, zaman damgalı veriler için idealdir ve belirli zaman aralıklarında veri sorgulamasını optimize eder. Örneğin, 2026’da akıllı şehir projeleri için trafik sensör verilerini işlemek.
Senaryo 3: Gerçek Zamanlı Önbellekleme ve Oturum Yönetimi
Düşük gecikme süresi, yüksek işlem hacmi ve geçici veri depolama.
En İyi Seçim: Redis
Web uygulamalarında kullanıcı oturumlarını, sık erişilen verileri veya API yanıtlarını önbelleğe almak için Redis rakipsizdir. Bellek içi mimarisi sayesinde milisaniyenin altında yanıt süreleri sunar. Ayrıca, Pub/Sub özellikleri ile gerçek zamanlı bildirim sistemleri veya oyun skor tabloları gibi senaryolarda da mükemmeldir. Bir e-ticaret sepetinin içeriğini veya bir kullanıcının son gezdiği sayfaları Redis’te tutmak, kullanıcı deneyimini önemli ölçüde hızlandırır.
Senaryo 4: Sosyal Ağlar ve Dolandırıcılık Tespiti
Karmaşık ilişkileri olan veriler ve derinlemesine bağlantı analizi.
En İyi Seçim: Neo4j
Sosyal ağlarda “kim kimi tanıyor”, “hangi grupların ortak üyeleri var” gibi sorular, geleneksel veritabanlarında çok sayıda JOIN işlemi gerektirir ve performansı düşürür. Neo4j, ilişkileri doğrudan depoladığı için bu tür sorgularda inanılmaz derecede hızlıdır. Dolandırıcılık tespitinde, şüpheli işlemler arasındaki gizli bağlantıları veya bir dolandırıcılık halkasındaki kişileri hızla ortaya çıkarmak için Neo4j’nin grafik yetenekleri vazgeçilmezdir. Bankacılık sektöründe, müşteri işlem ağlarını analiz ederek anormallikleri tespit etmek için sıklıkla kullanılır.
ÖNEMLİ NOKTA
Uygulama senaryonuzun “veri erişim modeli” ve “ilişki karmaşıklığı”, doğru NoSQL veritabanını seçmenizde en önemli faktörlerdir. Her veritabanı belirli bir iş yükü için optimize edilmiştir; genel amaçlı bir “her şeye uyan tek çözüm” yoktur.
Yukarıdaki mimari diyagramı, tek bir uygulama içinde farklı NoSQL veritabanlarının nasıl birlikte kullanılabileceğini göstermektedir. Örneğin, bir e-ticaret platformunda ürün katalogları için MongoDB, kullanıcı oturumları için Redis, geçmiş sipariş verileri için Cassandra ve ürün tavsiyeleri için Neo4j kullanılabilir. Bu “poliglottik kalıcılık” yaklaşımı, her bir servisin en iyi aracı kullanmasına olanak tanır.
DERİNLEMESİNE ANALİZ
Performans ve Ölçeklenebilirlik Analizi
Performans ve ölçeklenebilirlik, NoSQL veritabanlarının temel itici güçleridir. Ancak her birinin bu alanlarda farklı yaklaşımları ve güçlü yönleri vardır. Bu bölüm, dört veritabanının bu kritik metrikler açısından nasıl konumlandığını detaylıca inceleyecektir.
MongoDB: Esnek Ölçek ve Dengeli Performans
MongoDB, yatay ölçeklenebilirlik için sharding adı verilen bir mekanizma kullanır. Bu, veri kümelerini birden fazla sunucuya (shard) bölerek yüksek işlem hacmi ve depolama kapasitesi elde etmeyi sağlar. Her shard, verinin bir alt kümesini barındırır ve bağımsız olarak çalışır. Okuma ve yazma işlemleri genellikle replica setler aracılığıyla yüksek erişilebilirlik ve veri yedekliliği ile sağlanır. Ortalama okuma gecikmesi 5-50ms, yazma gecikmesi ise 10-100ms arasında değişebilir, bu da çoğu web uygulaması için fazlasıyla yeterlidir. 2026 itibarıyla, MongoDB Atlas gibi bulut çözümleri, sharding ve replica set yönetimini büyük ölçüde otomatize ederek ölçeklenebilirliği daha da kolaylaştırmaktadır.
Cassandra: Doğrusal Ölçeklenebilirlik ve Yüksek Erişilebilirlik
Cassandra, dağıtık mimarisi sayesinde doğrusal ölçeklenebilirlik sunar. Bu, kümeye daha fazla düğüm ekledikçe performansın da orantılı olarak artması anlamına gelir. Cassandra, özellikle yazma yoğun iş yüklerinde (saniyede milyonlarca yazma işlemi) üstündür ve tek bir hata noktası olmaksızın yüksek erişilebilirlik sağlar. Veriler, ağdaki birden fazla düğüme çoğaltılır ve tutarlılık seviyesi, uygulamanın ihtiyaçlarına göre ayarlanabilir. Okuma gecikmeleri 10-100ms, yazma gecikmeleri ise 5-50ms civarında olabilir. Özellikle büyük veri ve IoT senaryolarında, 2026’da hala en güvenilir çözümlerden biridir.
Redis: Işık Hızında Performans ve Bellek Kısıtlaması
Redis, bellek içi bir veritabanı olduğu için performans açısından mutlak bir şampiyondur. Okuma ve yazma gecikmeleri genellikle 1 milisaniyenin altındadır ve saniyede yüz binlerce işlem gerçekleştirebilir. Redis Cluster ile yatay ölçeklenebilirlik sağlansa da, temel kısıtlaması, tüm verilerin RAM’de tutulması gerektiğidir. Bu, büyük veri kümeleri için maliyeti artırabilir. Ancak, önbellekleme, oturum yönetimi ve gerçek zamanlı analizler gibi senaryolarda, Redis’in hızı rakipsizdir. 2026’da hala en popüler bellek içi veri deposu ve önbellek çözümü olmaya devam etmektedir.
Neo4j: İlişki Sorgularında Üstün Performans
Neo4j’nin performansı, ilişkisel derinliği olan sorgularda parlar. Düğümler ve kenarlar arasındaki doğrudan bağlantıları izleyerek, karmaşık grafik geçişleri (graph traversals) milisaniyeler içinde tamamlayabilir. Geleneksel veritabanlarında bu tür sorgular onlarca JOIN işlemi gerektireceğinden çok daha yavaş olacaktır. Neo4j, kümeleme (clustering) ve okuma replikaları ile ölçeklenebilirlik sunar. Özellikle 5-10 derinlikteki ilişki sorgularında 10-100ms gibi gecikme süreleri sunabilir. Ancak, basit anahtar-değer okuma/yazma veya yüksek hacimli toplu yazma işlemleri için en optimize çözüm değildir. 2026’da yapay zeka ve makine öğrenimi tabanlı tavsiye sistemlerinde kullanımı artmaktadır.
ÖNEMLİ NOKTA
Veritabanının performansı ve ölçeklenebilirliği, sadece ham hız rakamlarıyla değil, aynı zamanda projenizin özgül sorgu desenleri ve veri büyüme beklentileriyle değerlendirilmelidir. Her birinin kendi kullanım senaryosunda optimize edilmiş bir performans profili vardır.
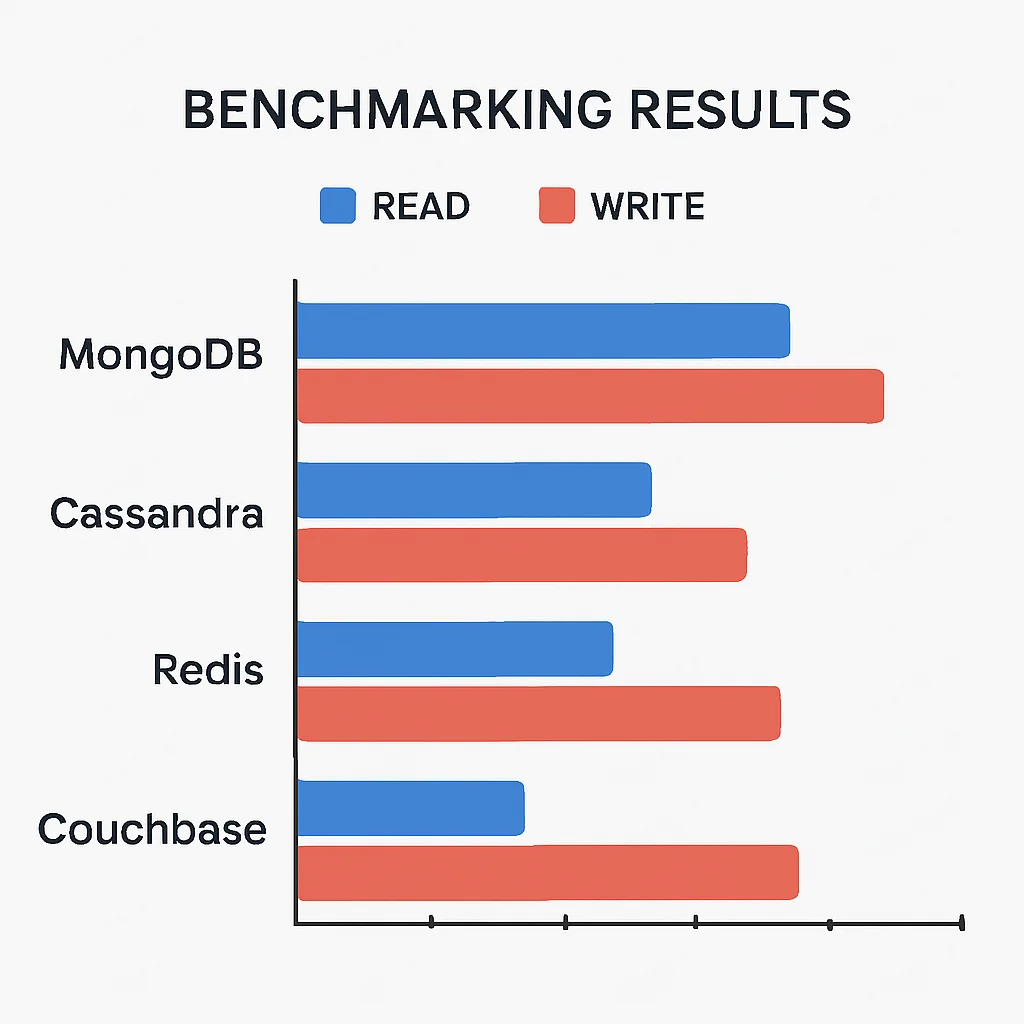
Yukarıdaki kıyaslama sonuçları, her bir veritabanının belirli iş yüklerinde nasıl performans gösterdiğini özetlemektedir. Unutulmamalıdır ki bu değerler, donanım, konfigürasyon ve veri modeli gibi faktörlere göre değişiklik gösterebilir.
Sıkça Sorulan Sorular (SSS)
Q. Hangi NoSQL veritabanı en hızlıdır?
Genel olarak, Redis bellek içi çalışma prensibi sayesinde milisaniyenin altında gecikme süreleri sunarak en hızlı NoSQL veritabanı olarak kabul edilir. Ancak bu, kullanım senaryosuna ve veri modelinin karmaşıklığına bağlıdır.
Q. Bir projede birden fazla NoSQL veritabanı kullanmak mümkün müdür?
Kesinlikle evet! Modern mikro hizmet mimarilerinde “poliglottik kalıcılık” adı verilen bir yaklaşım yaygın olarak kullanılır. Bu, uygulamanın farklı bölümlerinin (servislerin) kendi özel ihtiyaçlarına en uygun veritabanını seçmesi anlamına gelir. Örneğin, bir e-ticaret sitesi MongoDB’yi ürün katalogları için, Redis’i önbellekleme için ve Cassandra’yı geçmiş siparişler için kullanabilir.
Q. NoSQL veritabanları SQL veritabanlarının yerini tamamen alacak mı?
Hayır, NoSQL veritabanları SQL veritabanlarının yerini tamamen almayacak, daha ziyade onları tamamlayacaktır. SQL veritabanları, güçlü tutarlılık (ACID), karmaşık JOIN işlemleri ve yapılandırılmış veri için hala en iyi çözümdür. NoSQL ise esneklik, yatay ölçeklenebilirlik ve belirli veri modelleri için optimize edilmiştir. 2026’da ve sonrasında her iki tür veritabanının da kendi nişlerinde değerli olmaya devam etmesi beklenmektedir.
Q. Şema esnekliği ne anlama geliyor ve ne zaman avantajlıdır?
Şema esnekliği, belge tabanlı (MongoDB) ve sütun ailesi (Cassandra) gibi NoSQL veritabanlarının, her bir veri kaydının (belge veya satır) farklı alanlara sahip olabilmesi anlamına gelir. Bu, özellikle hızlı geliştirme döngülerinde, veri yapılarının sık değiştiği veya verilerin doğası gereği heterojen olduğu durumlarda büyük bir avantaj sağlar. Geliştiricilerin, veritabanı şemasını değiştirmek zorunda kalmadan yeni özellikler eklemesine olanak tanır.
Okuduğunuz için teşekkürler!
2026 yılı ve sonrasında backend projeleriniz için doğru NoSQL veritabanını seçmek, uygulamanızın başarısı için kritik bir adımdır. MongoDB, Cassandra, Redis ve Neo4j’nin her biri farklı güçlü yönlere sahip olup, projenizin özel ihtiyaçlarına göre değerlendirilmelidir. Umarım bu detaylı karşılaştırma, karar verme sürecinizde size yol göstermiştir.
Sorularınız mı var? Yorum bırakın veya Kwontrol ile iletişime geçin! Gelecek projelerinizde başarılar dileriz.