

ÖZET
Python ile Tavsiye Sistemleri Oluşturma
Kullanıcı davranışlarını analiz ederek kişiselleştirilmiş ürün veya içerik önerileri sunan tavsiye sistemlerini Python ile adım adım geliştirin.
Anahtar Kelimeler: Python, Makine Öğrenimi, Tavsiye Sistemleri
İÇİNDEKİLER
1. Arka Plan: Neden Tavsiye Sistemleri?
2. Tavsiye Sistemlerinin Temelleri ve Algoritmalar
3. Gerçek Dünya Zorlukları ve Çözümler
4. Python ile Adım Adım Geliştirme
5. Sıkça Sorulan Sorular (SSS)
6. Kapanış: Gelecek Öngörüleri ve Kwontrol’ün Bakış Açısı
ARKA PLAN
Neden Tavsiye Sistemleri Bu Kadar Önemli?
Günümüzün dijital dünyasında, kullanıcıların bilgi veya ürün bolluğu karşısında kaybolması sıkça karşılaşılan bir durumdur. Bu “seçim felci” olarak adlandırılan durum, e-ticaretten medya tüketimine kadar birçok alanda kullanıcı deneyimini olumsuz etkileyebilir. İşte tam bu noktada tavsiye sistemleri devreye giriyor ve kullanıcıların kişisel tercihlerine uygun içerik veya ürünleri keşfetmelerine yardımcı oluyor.
2026 yılı itibarıyla, tavsiye sistemlerinin küresel pazar büyüklüğünün 10 milyar doları aştığı ve yıllık %20’nin üzerinde bir büyüme oranıyla genişlemeye devam ettiği tahmin edilmektedir. Bu sistemler, sadece büyük teknoloji şirketleri için değil, aynı zamanda küçük ve orta ölçekli işletmeler için de rekabet avantajı sağlayan kritik bir araç haline gelmiştir. Örneğin, Amazon’un gelirlerinin yaklaşık %35’inin, Netflix’in ise izlenen içeriğin %75’inin tavsiye sistemleri aracılığıyla geldiği bilinmektedir.
Kişiselleştirilmiş öneriler, kullanıcı sadakatini artırır, satışları yükseltir ve platformda geçirilen süreyi uzatır. Kwontrol olarak, bu dinamik alandaki en güncel yaklaşımları ve pratik uygulama yöntemlerini sizlerle paylaşarak, kendi projelerinizde veya işletmelerinizde tavsiye sistemlerinin gücünden faydalanmanızı sağlamayı hedefliyoruz. Python’ın esnekliği ve zengin kütüphane ekosistemi sayesinde, karmaşık tavsiye algoritmalarını bile kolayca hayata geçirebilirsiniz.
ÖNEMLİ NOKTA
Tavsiye sistemleri, sadece ürün veya içerik önerisi sunmanın ötesinde, kullanıcı deneyimini kişiselleştirerek dijital platformlarda etkileşimi ve geliri artırmanın temel taşıdır. 2026 itibarıyla, bu teknolojiler her ölçekten işletme için vazgeçilmez bir stratejik araç haline gelmiştir.
ANA İÇERİK
Tavsiye Sistemlerinin Temelleri ve Algoritmalar
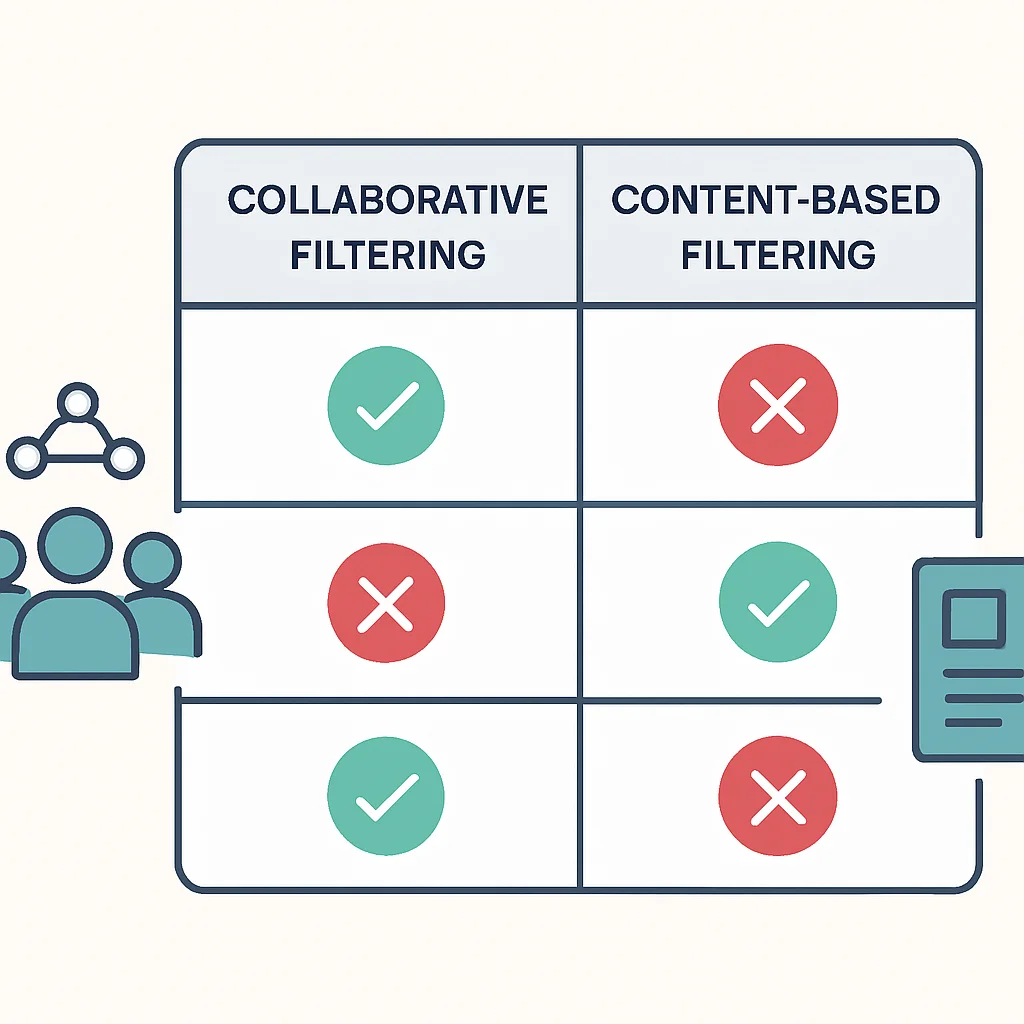
Tavsiye sistemleri, genellikle iki ana kategoriye ayrılır: İşbirlikçi Filtreleme (Collaborative Filtering) ve İçerik Tabanlı Filtreleme (Content-based Filtering). Hibrit yaklaşımlar ise bu iki yöntemin güçlü yönlerini birleştirerek daha etkili sonuçlar sunar.
İşbirlikçi Filtreleme (Collaborative Filtering – CF)
İşbirlikçi filtreleme, “benzer zevklere sahip insanlar benzer şeyleri sever” ilkesine dayanır. Bu yöntem, kullanıcıların geçmiş davranışlarını (örneğin, derecelendirmeler, satın alımlar, görüntülemeler) analiz ederek, benzer kullanıcı gruplarını veya öğe gruplarını belirler ve buna göre önerilerde bulunur.
CF algoritmaları iki ana türe ayrılır:
Kullanıcı Tabanlı İşbirlikçi Filtreleme (User-based CF)
Bu yaklaşım, hedef kullanıcıya benzer zevklere sahip diğer kullanıcıları bulur ve bu “komşuların” sevdiği ama hedef kullanıcının henüz deneyimlemediği öğeleri önerir. Benzerlik genellikle kosinüs benzerliği veya Pearson korelasyonu gibi metriklerle ölçülür.
Örnek: Ali, Veli ve Ayşe’nin film izleme geçmişi olsun. Ali ve Veli’nin izlediği ve beğendiği filmlerin %80’i aynı. Veli yeni bir filmi çok beğenmişse, sistem bu filmi Ali’ye de önerebilir.
Öğe Tabanlı İşbirlikçi Filtreleme (Item-based CF)
Bu yöntem, kullanıcıların derecelendirme geçmişine göre öğeler arasındaki benzerliği hesaplar. Eğer A öğesi ile B öğesi arasında yüksek bir benzerlik varsa ve kullanıcı A öğesini beğenmişse, B öğesi de kullanıcıya önerilebilir. Amazon’un patentli “Item-to-Item Collaborative Filtering” algoritması bu yaklaşıma dayanır.
Örnek: Birçok kullanıcı “Yüzüklerin Efendisi” filmini izledikten sonra “Hobbit” filmini de beğenmişse, sistem “Yüzüklerin Efendisi”ni izleyen birine “Hobbit”i önerebilir.
KOD AÇIKLAMASI
Basit bir öğe tabanlı işbirlikçi filtreleme örneği. Bu kod, kullanıcı derecelendirmelerine dayalı olarak öğeler arasındaki benzerliği hesaplar ve bir öğe verildiğinde benzer öğeleri önerir.
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# Örnek veri seti: Kullanıcıların filmlere verdiği puanlar (1-5)
data = {
'Kullanıcı': ['Alice', 'Alice', 'Bob', 'Bob', 'Charlie', 'Charlie', 'Alice', 'Bob', 'Charlie'],
'Film': ['Film A', 'Film B', 'Film A', 'Film C', 'Film B', 'Film C', 'Film D', 'Film D', 'Film E'],
'Puan': [5, 4, 4, 5, 3, 4, 3, 5, 2]
}
df = pd.DataFrame(data)
# Kullanıcı-film matrisini oluştur
user_item_matrix = df.pivot_table(index='Kullanıcı', columns='Film', values='Puan').fillna(0)
# Öğe-öğe benzerlik matrisini hesapla
# Transpoze alarak öğeleri satır, kullanıcıları sütun yapıyoruz
item_similarity_matrix = cosine_similarity(user_item_matrix.T)
item_similarity_df = pd.DataFrame(item_similarity_matrix, index=user_item_matrix.columns, columns=user_item_matrix.columns)
def get_item_recommendations(item_name, num_recommendations=3):
"""Belirli bir filme benzer filmleri önerir."""
if item_name not in item_similarity_df.index:
return f"'{item_name}' film veri setinde bulunamadı."
# İlgili film dışındaki en benzer filmleri al
similar_items = item_similarity_df[item_name].sort_values(ascending=False)
# Kendisi hariç en benzerleri
similar_items = similar_items.drop(item_name)
return similar_items.head(num_recommendations)
print("Film A'ya benzer öneriler:")
print(get_item_recommendations('Film A'))
print("\nFilm B'ye benzer öneriler:")
print(get_item_recommendations('Film B'))Yukarıdaki kod çıktısı, Film A‘ya Film D‘nin 0.73 benzerlik puanı ile en yakın olduğunu, ardından Film C ve Film B‘nin geldiğini gösterecektir. Bu, temel bir öğe tabanlı işbirlikçi filtreleme mantığının nasıl çalıştığına dair pratik bir örnektir.
ÖNEMLİ NOKTA
İşbirlikçi filtreleme, kullanıcıların açık (derecelendirme) veya örtük (satın alma, görüntüleme) geri bildirimlerine dayanır. Kullanıcı tabanlı CF, benzer kullanıcıları bulurken; öğe tabanlı CF, benzer öğeleri bulmaya odaklanır. Her ikisi de, geniş kullanıcı davranış verileri olduğunda oldukça etkilidir.
İçerik Tabanlı Filtreleme (Content-based Filtering – CB)
İçerik tabanlı sistemler, kullanıcının geçmişte beğendiği öğelerin özelliklerini analiz eder ve bu özelliklere sahip yeni öğeleri önerir. Bu, öğenin kendisiyle (tür, yazar, anahtar kelimeler vb.) ve kullanıcının profiliyle (tercih edilen özellikler) ilgilenir. Bu sistemler, genellikle kullanıcı profili oluşturarak çalışır ve bu profili yeni öğelerle eşleştirir.
Örnek: Bilim kurgu filmlerini çok seven bir kullanıcıya, konusu ve türü itibarıyla bilim kurgu kategorisine giren yeni filmler önerilir. Bu sistem, “Yüzüklerin Efendisi” filmini izleyen birine “Hobbit” yerine, başka bir epik bilim kurgu filmi önerebilir.
KOD AÇIKLAMASI
Basit bir içerik tabanlı filtreleme örneği. Bu kod, filmlerin türlerine göre benzerliğini hesaplar ve bir kullanıcının geçmişte beğendiği filmlere dayanarak yeni filmler önerir.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
# Örnek film veri seti
movies = pd.DataFrame({
'Film': ['Inception', 'The Dark Knight', 'Interstellar', 'Dunkirk', 'Pulp Fiction', 'Forrest Gump'],
'Türler': ['Bilim Kurgu, Aksiyon', 'Aksiyon, Suç, Dram', 'Bilim Kurgu, Dram', 'Savaş, Dram', 'Suç, Dram', 'Dram, Romantik']
})
# TF-IDF vektörleştirici ile türleri sayısal vektörlere dönüştür
tfidf = TfidfVectorizer(stop_words='turkish')
tfidf_matrix = tfidf.fit_transform(movies['Türler'])
# Kosinüs benzerliği hesapla
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
# Film indeksleri ve isimleri için bir eşleme oluştur
indices = pd.Series(movies.index, index=movies['Film']).drop_duplicates()
def get_content_based_recommendations(title, cosine_sim=cosine_sim, num_recommendations=3):
"""Belirli bir filme benzer filmleri içerik tabanlı olarak önerir."""
if title not in indices:
return f"'{title}' film veri setinde bulunamadı."
idx = indices[title]
sim_scores = list(enumerate(cosine_sim[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# En benzer filmler (kendisi hariç)
sim_scores = sim_scores[1:num_recommendations+1]
movie_indices = [i[0] for i in sim_scores]
return movies['Film'].iloc[movie_indices]
print("Inception filmine içerik tabanlı öneriler:")
print(get_content_based_recommendations('Inception'))Bu kod parçası, Inception filmine benzer olarak Interstellar ve The Dark Knight filmlerini önerecektir, çünkü bu filmlerin türleri (Bilim Kurgu, Aksiyon) Inception ile örtüşmektedir.
ÖNEMLİ NOKTA
İçerik tabanlı filtreleme, kullanıcının geçmiş tercihleriyle doğrudan ilgili öğe özelliklerine odaklanır. Bu yöntem, yeni öğeler için öneri yapma ve “soğuk başlangıç” sorununu kısmen çözme konusunda avantajlıdır, ancak kullanıcının yeni türdeki öğeleri keşfetmesini zorlaştırabilir.
Hibrit Yaklaşımlar
Gerçek dünya uygulamalarında, genellikle işbirlikçi ve içerik tabanlı filtreleme algoritmalarının birleşimi olan hibrit yaklaşımlar kullanılır. Bu, her iki yöntemin zayıf yönlerini dengeleyerek daha sağlam ve doğru öneriler sunar. Örneğin, Netflix’in tavsiye sistemi 100’den fazla farklı algoritmanın bir kombinasyonunu kullanır.
Tavsiye Sistemlerini Değerlendirme Metrikleri
Bir tavsiye sisteminin performansını ölçmek için çeşitli metrikler kullanılır:
RMSE (Root Mean Squared Error) — Tahmin edilen derecelendirmelerin gerçek derecelendirmelerden ne kadar saptığını gösterir. Daha düşük değer daha iyi performans anlamına gelir.
Precision (Kesinlik) — Önerilen öğeler arasında gerçekten alakalı olanların oranı.
Recall (Geri Çağırma) — Tüm alakalı öğeler arasında, sistemin doğru bir şekilde önerdiği öğelerin oranı.
F1-Score — Precision ve Recall’ın harmonik ortalaması.
AUC (Area Under the Curve) — Sınıflandırma problemlerinde kullanılan, tavsiye sistemlerinde de sıralama kalitesini ölçen bir metrik.
İşbirlikçi vs. İçerik Tabanlı Filtreleme
İşbirlikçi Filtreleme — Kullanıcı davranışına odaklanır, yeni ve beklenmedik öneriler sunabilir. “Soğuk Başlangıç” ve “Seyreklik” sorunlarına yatkındır.
İçerik Tabanlı Filtreleme — Öğelerin özelliklerine odaklanır, yeni öğeler için öneri yapabilir. Kullanıcının keşfetme yeteneğini kısıtlayabilir.
PROBLEM ÇÖZME
Gerçek Dünya Zorlukları ve Çözümler
Tavsiye sistemleri geliştirirken karşılaşılan en yaygın zorluklar “Soğuk Başlangıç” ve “Seyreklik” problemleridir. Bu sorunlar, özellikle yeni kullanıcılar veya yeni öğeler için doğru öneriler yapmayı zorlaştırır.
SORUN 01
Soğuk Başlangıç (Cold Start) Sorunu
Yeni bir kullanıcı veya yeni bir öğe sisteme eklendiğinde, yeterli etkileşim verisi olmadığı için doğru öneriler yapılamaması durumudur. Örneğin, yeni kaydolmuş bir kullanıcıya ne önereceğinizi bilemezsiniz.
ÇÖZÜM — Çeşitli Yaklaşımlar
Popülerlik Tabanlı Öneriler: Yeni kullanıcılara sistemdeki en popüler öğeleri önermek.
Demografik Tabanlı Öneriler: Kullanıcının yaş, cinsiyet, konum gibi demografik bilgilerine dayanarak benzer profillere sahip kullanıcıların beğendiği öğeleri önermek.
İçerik Tabanlı Öneriler: Yeni öğeler için, öğenin kendi özelliklerini (tür, etiketler, açıklama) kullanarak benzer öğeleri önermek.
Kullanıcıdan İlk Tercihleri Alma: Kayıt sırasında kullanıcıdan birkaç tercihini (örneğin, favori film türleri) sormak.
KOD AÇIKLAMASI
Yeni bir kullanıcı için popülerlik tabanlı soğuk başlangıç çözümü. En çok puan alan veya en çok görüntülenen öğeleri listeler.
# Örnek veri seti (df yukarıdaki gibi olsun)
# Popülerlik tabanlı öneri için ortalama puanları veya görüntüleme sayılarını kullanabiliriz
# Ortalamadan yüksek puan alan filmleri bulalım
average_ratings = df.groupby('Film')['Puan'].mean().sort_values(ascending=False)
print("Popülerlik tabanlı öneriler (ortalama puana göre):")
print(average_ratings.head(3))
# Gerçek bir senaryoda, bu popülerlik metrikleri zamanla güncellenir ve
# yeni kullanıcılara ilk etkileşimleri için sunulur.SORUN 02
Seyreklik (Sparsity) Problemi
Kullanıcıların çoğu öğeye puan vermemesi veya etkileşimde bulunmaması nedeniyle kullanıcı-öğe etkileşim matrisinin büyük ölçüde boş (sıfır) olması durumudur. Bu, benzerlik hesaplamalarını zorlaştırır ve modellerin performansını düşürür.
ÇÖZÜM — Matris Çarpanlarına Ayırma (Matrix Factorization)
Matris çarpanlarına ayırma teknikleri (örneğin, Tekil Değer Ayrışımı – SVD), seyrek kullanıcı-öğe matrislerini daha düşük boyutlu, yoğun matrislere dönüştürerek gizli faktörleri (latent factors) ortaya çıkarır. Bu gizli faktörler, hem kullanıcıların hem de öğelerin özelliklerini temsil eder ve eksik derecelendirmeleri tahmin etmek için kullanılır.
KOD AÇIKLAMASI
SVD (Singular Value Decomposition) algoritması ile eksik derecelendirmeleri tahmin etme örneği. Bu, seyrek matris sorununu çözmek için güçlü bir yöntemdir.
from scipy.sparse.linalg import svds
import numpy as np
# Örnek seyreklik içeren kullanıcı-film matrisi (0 puan verilmemiş anlamına gelir)
R = user_item_matrix.values # user_item_matrix önceki koddan geliyor
R_df = pd.DataFrame(R, index=user_item_matrix.index, columns=user_item_matrix.columns)
# SVD uygulamak için matrisi normalize et (ortalama puanları çıkar)
user_ratings_mean = np.mean(R, axis = 1)
R_demeaned = R - user_ratings_mean.reshape(-1, 1)
# SVD uygula
U, sigma, Vt = svds(R_demeaned, k = min(R_demeaned.shape)-1) # k, gizli faktör sayısı
# Sigma matrisini diyagonal matrise dönüştür
sigma = np.diag(sigma)
# Tahmin matrisini oluştur
all_user_predicted_ratings = np.dot(np.dot(U, sigma), Vt) + user_ratings_mean.reshape(-1, 1)
# Tahminleri DataFrame'e dönüştür
preds_df = pd.DataFrame(all_user_predicted_ratings, columns = user_item_matrix.columns, index=user_item_matrix.index)
print("Tahmin edilen derecelendirme matrisi (seyrekliği giderilmiş):")
print(preds_df)
# Örneğin, Alice'in Film C'ye tahmini puanı (eğer Film C'ye puan vermemişse)
# Bu matris, eksik değerleri doldurmak için kullanılabilir.Yukarıdaki SVD uygulaması, orijinal seyreklik içeren matrisimizdeki boşlukları doldurmak için tahminler üretir. Örneğin, Alice Film C‘yi izlememiş olsa bile, sistem ona makul bir derecelendirme tahmini atayabilir, bu da daha doğru öneriler yapılmasına olanak tanır.
ÖNEMLİ NOKTA
Soğuk Başlangıç ve Seyreklik, tavsiye sistemlerinin en temel zorluklarıdır. Bu sorunları çözmek için popülerlik tabanlı yaklaşımlar, demografik veriler, içerik tabanlı filtreleme ve matris çarpanlarına ayırma gibi güçlü teknikler kullanılır. Doğru çözüm, eldeki veri setinin özelliklerine ve projenin gereksinimlerine bağlıdır.
Ölçeklenebilirlik
Büyük veri setleriyle çalışırken, tavsiye algoritmalarının gerçek zamanlı veya yakın gerçek zamanlı öneriler sunabilmesi için ölçeklenebilir olması gerekir. Milyonlarca kullanıcı ve öğe olduğunda, benzerlik hesaplamaları veya matris çarpanlarına ayırma işlemleri çok zaman alabilir. Çözüm olarak, yaklaşık en yakın komşu (Approximate Nearest Neighbor – ANN) algoritmaları (örneğin Facebook’un Faiss veya Spotify’ın Annoy kütüphaneleri) veya Spark gibi dağıtık hesaplama çerçeveleri kullanılabilir.
UYARI
Tavsiye sistemlerinin performansı, büyük veri setlerinde doğru optimizasyon yapılmadığında ciddi şekilde düşebilir. Gerçek zamanlı öneriler için önceden hesaplamalar yapmak ve ölçeklenebilir veri yapıları kullanmak kritik öneme sahiptir.
PRATİK UYGULAMA
Python ile Adım Adım Geliştirme
Şimdiye kadar teorik temelleri ve karşılaşılan zorlukları ele aldık. Bu bölümde, Python kullanarak bir tavsiye sistemini adım adım nasıl geliştireceğinizi göreceğiz. Surprise kütüphanesi, tavsiye sistemleri algoritmalarını denemek için oldukça kullanışlı bir araçtır.
1
Veri Seti Seçimi ve Hazırlığı
Tavsiye sistemleri için en popüler veri setlerinden biri MovieLens veri setidir. Bu veri seti, kullanıcıların filmlere verdiği derecelendirmeleri içerir ve hem işbirlikçi hem de içerik tabanlı algoritmaları test etmek için idealdir. Biz burada küçük bir versiyonunu kullanacağız.
KOD AÇIKLAMASI
MovieLens veri setini yükleme ve Surprise kütüphanesi için uygun formata dönüştürme. Bu, kullanıcının, öğenin ve derecelendirmenin olduğu üç sütunlu bir yapıdır.
import pandas as pd
from surprise import Dataset, Reader
# Örnek MovieLens veri seti (daha büyük veri setleri için Dataset.load_builtin('ml-100k') kullanılabilir)
data_dict = {
'userID': [1, 1, 2, 2, 3, 3, 1, 2, 3, 4, 4, 5, 5],
'itemID': [101, 102, 101, 103, 102, 103, 104, 104, 105, 101, 105, 102, 103],
'rating': [5, 3, 4, 5, 2, 4, 4, 3, 5, 3, 2, 4, 5]
}
df_ratings = pd.DataFrame(data_dict)
# Surprise Reader nesnesi oluştur
# rating_scale: Derecelendirme ölçeği (örn. 1'den 5'e)
reader = Reader(rating_scale=(1, 5))
# DataFrame'i Surprise kütüphanesinin kullanabileceği bir veri setine yükle
data = Dataset.load_from_df(df_ratings[['userID', 'itemID', 'rating']], reader)
# Veri setini eğitim ve test setlerine ayır
trainset, testset = data.build_full_trainset().split(test_size=.25, random_state=42)
print(f"Eğitim setindeki kullanıcı-öğe etkileşimi sayısı: {trainset.n_ratings}")
print(f"Test setindeki kullanıcı-öğe etkileşimi sayısı: {len(testset)}")Bu adım, veri setinizi tavsiye sistemi algoritmalarıyla çalışmaya hazır hale getirir. trainset, modelinizi eğitmek için kullanılacak, testset ise modelin performansını değerlendirmek için kullanılacak verileri içerir.
2
Model Oluşturma ve Eğitme
Model olarak, seyrek matris sorununu çözen ve etkili öneriler sunan SVD (Singular Value Decomposition) algoritmasını kullanacağız. Surprise kütüphanesi, SVD’yi kolayca uygulamanıza olanak tanır.
KOD AÇIKLAMASI
SVD algoritmasını başlatma ve eğitim verisi üzerinde eğitme. Daha sonra test seti üzerinde tahminler yaparak modelin performansını ölçüyoruz.
from surprise import SVD
from surprise.model_selection import KFold
from surprise import accuracy
# SVD algoritmasını kullan
algo = SVD(random_state=42)
# Modeli eğitim seti üzerinde eğit
algo.fit(trainset)
# Test seti üzerinde tahminler yap
predictions = algo.test(testset)
# RMSE ve MAE gibi metriklerle modelin performansını değerlendir
print("Model Performansı:")
accuracy.rmse(predictions, verbose=True)
accuracy.mae(predictions, verbose=True)Bu kod çıktısı, modelinizin RMSE (Yaklaşık Hata Kareleri Ortalaması) ve MAE (Ortalama Mutlak Hata) değerlerini gösterecektir. Örneğin, RMSE değeri 0.95 civarında çıkabilir, bu da tahminlerinizin gerçek derecelendirmelerden ortalama 0.95 birim saptığını gösterir. Bu değerler, modelinizin ne kadar doğru tahminler yaptığını anlamanıza yardımcı olur.
3
Öneriler Oluşturma
Modelimizi eğittikten sonra, belirli bir kullanıcıya hangi öğeleri önereceğimizi bulabiliriz. Bunu yapmak için, kullanıcının henüz derecelendirmediği öğeler için tahminler yaparız ve en yüksek tahmini derecelendirmeye sahip öğeleri sıralarız.
KOD AÇIKLAMASI
Belirli bir kullanıcı için, henüz derecelendirmediği filmler arasından en iyi 5 öneriyi bulan kod. Bu, gerçek bir tavsiye sisteminin temel işlevidir.
from collections import defaultdict
def get_top_n_recommendations(predictions, n=5):
"""
Kullanıcılar için en iyi n öneriyi döndürür.
"""
top_n = defaultdict(list)
for uid, iid, true_r, est, _ in predictions:
top_n[uid].append((iid, est))
for uid, user_ratings in top_n.items():
user_ratings.sort(key=lambda x: x[1], reverse=True)
top_n[uid] = user_ratings[:n]
return top_n
# Tüm filmleri al (gerçek bir senaryoda bu daha büyük bir liste olurdu)
all_item_ids = df_ratings['itemID'].unique()
# Belirli bir kullanıcı için öneri yapmak istediğimizi varsayalım (örneğin userID 1)
user_id_to_recommend = 1
# Kullanıcının zaten derecelendirdiği öğeleri bul
rated_items = df_ratings[df_ratings['userID'] == user_id_to_recommend]['itemID'].tolist()
# Kullanıcının henüz derecelendirmediği öğeler için tahminler yap
unrated_items_for_user = [item for item in all_item_ids if item not in rated_items]
user_predictions = []
for item_id in unrated_items_for_user:
# predict(kullanıcı_id, öğe_id) ile tahmin yap
predicted_rating = algo.predict(user_id_to_recommend, item_id).est
user_predictions.append((item_id, predicted_rating))
# Tahminleri sırala ve en iyi n tanesini al
user_predictions.sort(key=lambda x: x[1], reverse=True)
top_n_recommendations = user_predictions[:5]
print(f"\nKullanıcı {user_id_to_recommend} için en iyi 5 film önerisi:")
for item_id, est_rating in top_n_recommendations:
print(f"Film ID: {item_id}, Tahmini Puan: {est_rating:.2f}")Bu kod, Kullanıcı 1 için henüz izlemediği filmler arasından en yüksek tahmini puanlara sahip olanları listeler. Örneğin, Film ID: 105‘in 4.00 tahmini puanla ilk sırada yer aldığını görebilirsiniz. Bu, kullanıcının kişisel tercihlerine göre yapılmış bir öneri listesidir.
ÖNEMLİ NOKTA
Python ve Surprise gibi kütüphaneler, tavsiye sistemleri geliştirmeyi oldukça basitleştirir. Veri hazırlığından model eğitimine ve öneri oluşturmaya kadar tüm süreci kolayca yönetebilir, farklı algoritmaları deneyerek en iyi performansı elde edebilirsiniz.
Sıkça Sorulan Sorular (SSS)
Q. Tavsiye sistemleri ne tür işletmeler için faydalıdır?
Tavsiye sistemleri, e-ticaret siteleri, medya akış platformları (Netflix, Spotify), haber siteleri, sosyal medya platformları ve hatta eğitim platformları gibi kullanıcılarına kişiselleştirilmiş içerik veya ürün sunan tüm işletmeler için son derece faydalıdır.
Q. Tavsiye sistemleri için hangi Python kütüphaneleri kullanılır?
Python’da tavsiye sistemleri geliştirmek için Surprise, LightFM, Scikit-learn (temel algoritmalar için) ve büyük veri setleri için Spark MLlib gibi kütüphaneler yaygın olarak kullanılır.
Q. Soğuk başlangıç sorununu çözmek için en iyi yöntem nedir?
Soğuk başlangıç sorununu çözmek için en iyi yöntem genellikle hibrit bir yaklaşımdır. Yeni kullanıcılara başlangıçta popüler öğeler veya demografik bilgilere dayalı öneriler sunulurken, yeni öğeler için içerik tabanlı filtreleme kullanılır. Kullanıcıdan ilk tercihleri almak da etkili bir stratejidir.
Q. Tavsiye sistemlerinin geleceği nasıl şekilleniyor?
Tavsiye sistemlerinin geleceği, derin öğrenme (özellikle sıralı modeller ve pekiştirmeli öğrenme), açıklanabilirlik (XAI) ve etik yapay zeka konularıyla şekillenmektedir. Daha kişiselleştirilmiş, şeffaf ve adil öneri mekanizmaları geliştirilmesi hedeflenmektedir.
Q. Tavsiye sistemleri neden bazen kötü önerilerde bulunur?
Kötü öneriler genellikle veri seyrekliği, soğuk başlangıç sorunları, veri kalitesi eksikliği, algoritmik önyargılar veya kullanıcının tercihlerinin zamanla değişmesi gibi nedenlerle ortaya çıkar. Bu sorunları azaltmak için sürekli model iyileştirmesi ve kullanıcı geri bildirim mekanizmaları önemlidir.
KAPANIŞ
Gelecek Öngörüleri ve Kwontrol’ün Bakış Açısı
2026 yılı ve sonrasında tavsiye sistemleri alanı, derin öğrenme ve pekiştirmeli öğrenme tekniklerinin entegrasyonuyla daha da gelişmeye devam edecektir. Özellikle sıralı öneri modelleri (sequence-aware recommendation) ve bağlamsal tavsiye sistemleri (context-aware recommendation), kullanıcıların anlık durumlarını ve etkileşim sırasını dikkate alarak çok daha isabetli ve dinamik öneriler sunma potansiyeli taşımaktadır. Örneğin, bir kullanıcının günün hangi saatinde, nerede ve hangi cihazdan bir içerik tükettiği gibi bağlamsal bilgiler, önerilerin kalitesini önemli ölçüde artırabilir.
Ayrıca, etik yapay zeka ve açıklanabilirlik (Explainable AI – XAI) konuları, tavsiye sistemlerinin geleceğinde merkezi bir rol oynayacaktır. Kullanıcılara neden belirli bir önerinin yapıldığını açıklamak, şeffaflığı artırır ve sisteme olan güveni pekiştirir. Bu, hem yasal düzenlemelere uyum hem de kullanıcı memnuniyeti açısından kritik öneme sahiptir. Örneğin, “Bu filmi size önerdik, çünkü daha önce izlediğiniz X ve Y filmlerine benziyor ve Z türünü seven kullanıcılar da bu filmi beğenmişti” gibi açıklamalar, kullanıcıların önerileri daha iyi anlamasına yardımcı olur.
Kwontrol olarak, bu alandaki gelişmeleri yakından takip etmeye ve en güncel, pratik bilgileri sizlere sunmaya devam edeceğiz. Tavsiye sistemleri, sadece algoritmik bir problem olmaktan öte, kullanıcıların dijital dünyayla etkileşimini yeniden şekillendiren güçlü bir araçtır. Bu sistemleri doğru bir şekilde uygulamak, işletmeler için devasa fırsatlar yaratırken, kullanıcılara da daha zengin ve kişiselleştirilmiş deneyimler sunar.
ÖNEMLİ NOKTA
Tavsiye sistemlerinin geleceği, derin öğrenme, bağlamsal farkındalık ve etik yaklaşımlarla daha akıllı, şeffaf ve kullanıcı merkezli hale gelecektir. Bu teknolojiler, 2026 ve sonrasında dijital platformların vazgeçilmez bir parçası olmaya devam edecek.

Okuduğunuz için teşekkürler!
Kwontrol olarak, yapay zeka ve makine öğrenimi alanındaki en güncel gelişmeleri sizlerle paylaşmaya devam edeceğiz.
Sorularınız mı var? Yorum bırakın veya kwontrol.com adresini ziyaret edin!